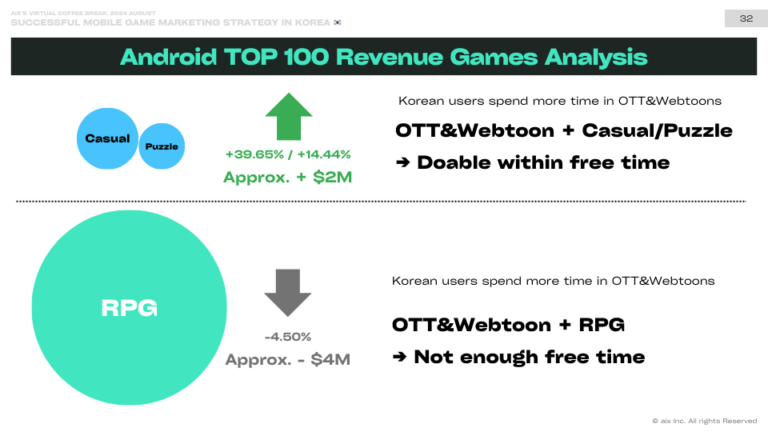
In July, US-based Sarah Silverman, Christopher Golden, and Richard Cardray took ChatGPT developer OpenAI to court for alleged intellectual property (IP) violations. In a recent court filing, Meta urged the court to dismiss the plaintiffs' claims that Facebook infringed on their creative works while training its AI models. Meta argued that its generative AI model, LLaMA 2, did not violate intellectual property laws and was prepared under the "fair use" doctrine. "The use of text to train LLaMA to statistically model language and generate original expression is inherently innovative and constitutes classic fair use," Meta said in its motion to dismiss.
지난 7월, 미국에 거주하는 사라 실버만, 크리스토퍼 골든, 리처드 카드레이는 지적 재산권(IP) 위반 혐의로 ChatGPT 개발사인 OpenAI를 법정에 세웠습니다. 최근 법원에 제출한 소장에서 메타는 페이스북이 AI 모델을 학습하는 과정에서 창작물의 저작권을 침해했다는 원고들의 주장을 기각해 줄 것을 법원에 촉구했다. 메타는 자사의 생성형 AI 모델인 LLaMA 2가 지적재산권법을 위반하지 않고 '공정 사용' 원칙에 따라 준비되었다고 주장했다. 메타는 기각 신청서에서 "언어를 통계적으로 모델링하고 독창적인 표현을 생성하기 위해 LLaMA를 훈련시키는 데 텍스트를 사용하는 것은 본질적으로 혁신적이며 전형적인 공정 사용에 해당한다"라고 밝혔다.