SNS에 유통되는 콘텐츠 그리고 인공지능 학습을 위한 데이터
사전예고나 별다른 프로모션이나 이렇다 할 광고 하나 없이 조용하게 등장했던 챗GPT의 파급력과 존재감은 그야말로 남달랐다. 업계에서는 "챗GPT 써보셨어요?"라고 말할 정도다. "들어보셨나요?" 수준도 아니고 실제로 경험해 봤냐는 질문이 더 많았다. 챗GPT를 기점으로 인공지능 챗봇을 포함해 관련 서비스나 플랫폼 모두 (마치 발등에 불이라도 떨어진 듯) 고도화나 신규 개발을 진행하고 있는 추세다. 덕분에 이와 관련된 주식 종목도 한때 화제가 되기도 했었다. 어떻게 엮든 챗GPT를 통한 비즈니스 모델은 무궁무진한 것처럼 보이는데 이를 어디서부터 다루면 되는 것인지 아직까진 (개인적으로) '물음표'다. 저 멀리 '챗GPT'라는 실체가 명확하게 보이는데도 그냥 넓은 안갯속을 걷는 것 같다. 물론 어딘가에서는 이미 잘 엮고 있을지도 모를 일이겠다.
챗GPT를 개발한 오픈 AI는 2015년 미국 샌프란시스코에서 출발했다. 샘 알트먼과 일론 머스크가 공동의장으로 자리하고 있는 오픈 AI가 지금의 챗GPT를 이룩하였으며 이후 마이크로소프트(MS)와 파트너십을 맺기도 했다. 2023년 1월 기준으로 보면 오픈 AI의 기업가치는 대략 290억 달러, 한화로 약 38조 원 수준이라고 한다. 챗GPT를 한 번쯤 써봤다면 알 수 있을 테지만 사용자의 쿼리에 대한 답변을 보면 놀랍지 않을 수 없다. 인공지능이 유저들의 질문을 받아 그에 맞는 답을 해준다는 것은 측정할 수 없을 만큼의 방대한 데이터에서 답을 추출하여 내놓는다는 것인데 데이터가 많으면 많을수록 그리고 우리가 흔히 말하는 머신러닝과 딥러닝이 제대로 되어 있을수록 더 좋은 결과물을 내놓을 수 있다. 그렇다면 학습에 필요한 데이터는 어디에서 왔을까?
 인공지능 학습에 필요한 데이터. 출처 : Bernard Marr
인공지능 학습에 필요한 데이터. 출처 : Bernard Marr
챗GPT라는 존재가 산업 전반에 엄청난 변화를 일으키자 인공지능을 기반으로 하는 테크 기업들 역시 세상에 널려있는 데이터를 수집해 융합하고 또 활용하고 있다. 때로 MOU를 맺기도 하고 콘텐츠 공급에 따른 계약이 이뤄지기도 하며 웹에서 크롤링해서 가져가는 경우도 더러 있다. 본래 데이터란 인공지능의 학습 재료가 되는데 이러한 데이터에도 뉴스 콘텐츠가 들어가게 되니 뉴스를 생산하는 미디어연합체 역시 이에 대한 사용료가 책정되어야 한다고 목소리를 높였다. AI 챗봇은 꾸준하게 늘어나는 실정인데 실제로 계약이 이루어져 사용료를 지급하는 경우는 (거의) 없다고 한다.
오픈 AI의 공동의장이면서 테슬라의 수장이자 트위터를 손에 쥔 최고경영자 일론 머스크가 이런 언급을 했다. "트위터에서 기사 1건을 클릭해 본문을 보려고 하는 경우 요금을 청구할 수 있도록 하겠다"라고.
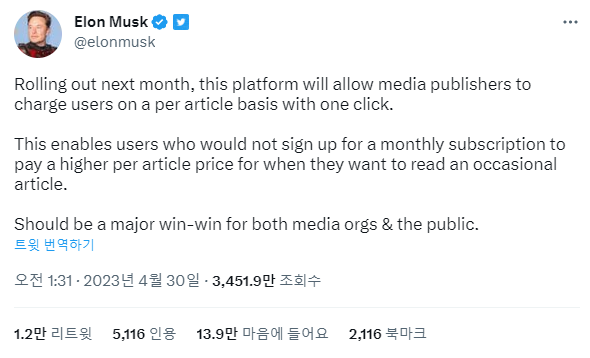
일론 머스크가 지난 4월 30일 남긴 트윗. 출처 : 일론 머스크 트위터
대충 번역하면, 월간 구독에 가입하지 않은 유저가 가끔 기사를 보고 싶을 때 사용료를 낼 수 있도록 하는데 미디어 입장에서 보면 월 구독료보다 더 높은 금액을 책정할 수 있도 유저 입장에서는 꼭 구독을 하지 않더라도 적정한 가격에 기사를 볼 수 있으니 '윈윈'할 수 있다고 말한다.
페이스북(Facebook)이나 레딧(Reddit)과 소셜 네트워크 서비스에서도 독자가 흥미를 가질법한 기사를 발견한 경우 기사 전문을 보려고 웹에 진입하는 경우들이 종종 있다. 기사 전체를 볼 수 있도록 충분히 오픈하는 경우도 있지만 페이월에 막혀 기사 전체를 볼 수 없거나 정해진 횟수만큼 제한적으로 보는 케이스도 있고 월 구독으로 유도하는 경우도 있다. 물론 이는 언론사나 미디어가 어떻게 설정하느냐에 따라 다를 것이다. 일론 머스크가 말하는 기사 소비에 대한 소액의 구독료 청구 취지는 '언론사 웹사이트의 월 구독보다 기사 1건당 그에 맞는 요금을 책정할 수 있어 시너지 효과가 나게 될 것'이라는 것이다. 더불어 1건의 기사를 소비하는 구독료를 책정하게 되면 1개월 구독료보다 조금 더 높게 책정할 수 있다는 것도 나름 그럴듯한 생각인 것 같다. 물론 미디어가 형성하고 있는 콘텐츠 소비 환경 등을 전반적으로 고려해야 할 것이다. 아무튼 미디어 기업들이 꾸준하게 추진하던 콘텐츠 유료화라는 부분에 빅테크 기업이 직접 나선 것이라 여기에는 긍정적인 목소리도 있지만 그렇지 않은 의견도 있다. 결국엔 미디어기업의 유료화와 빅테크의 동참 자체를 두고서도 찬반론이 있다는 것이다. 하긴 그게 무엇이든 찬반론은 늘 따라다니는 것 같다.

Instant Articles by Facebook 출처 : marketing-seo.it
앞서 언급했던 페이스북의 경우에도 온라인에서 유통되는 수많은 콘텐츠를 통해 독자들을 모았고 수익도 낼 수 있었다. 인사이트, 위키트리, 허핑턴포스트와 같은 인터넷 미디어도 페이스북을 통해 급부상하기도 했었다(물론 지금은 상황이 조금 다르긴 하다) 또한 페이스북은 인스턴트 아티클스(Instant Articles)라는 서비스를 통해 언론사 기사를 제공하기도 했다. 뉴욕타임스, 버즈피드, 가디언, 슈피겔 등 거대한 미디어가 여기에 참여했다. 독자들은 기사에 쉽게 접근할 수 있었다. 페이스북은 광고를 붙여 언론사와 나눠 갖기도 했다. 5년도 넘게 서비스했던 인스턴트 아티클스는 10년도 채우지 못하고 종료되었다. 일종의 이데올로기를 과도하게 내세울 수 있는 정치적 창구가 될 수도 있다는 비판도 있었는데 실제론 뉴스 소비층 자체도 매우 적었다고 한다. 투자 대비 성과가 없었으니 자연스럽게 종료하는 수순을 밟은 셈이다. 그럼에도 페이스북은 분명히 거대한 SNS 플랫폼이었다. 일부 미디어는 페이스북을 통해 자신의 몸집을 제대로 키우기도 했다.
2022년 미국 의회는 '언론사들이 플랫폼 기업과 수익 배분을 협의할 수 있는 이른바 <저널리즘 경쟁과 보호에 관한 법률>(JCPA, Journalism Competition & Preservation Act)를 내세운 적이 있다. 미국의 미디어 기업이 모였다고 할 수 있는 연합체는 '빅테크의 오랜 시간 콘텐츠 남용을 견뎌낼 수 있는 여력이 없으니 JCPA 입법을 촉구했다'라고 한다. 이에 빅테크 기업들은, 특히 페이스북은 이 법률이 통과되면 페이스북 내에서 뉴스 콘텐츠가 유통되지 못하도록 차단할 것이라고 대응했다고 한다.
※ JCPA에 관한 웹사이트 : https://www.newsmediaalliance.org/digital-programs-and-advocacy/safe-harbor-resource-center/JCPA Resource Center | News/Media AllianceThis page contains resources for members on the Journalism Competition & Preservation Act (JCPA), which would allow publishers to collectively negotiate with the tech platforms.www.newsmediaalliance.org
SNS라는 플랫폼을 통해 유통되는 뉴스 콘텐츠로 구독자를 모았고 수익도 냈는데 언론사에는 아무런 대가가 없었다는 것이 이유다. 혹자는 '자신들(미디어)의 몸집과 영향력을 키우기 위해 스스로 콘텐츠를 유통하고 있고 누군가의 콘텐츠 공유 하나만으로도 트래픽을 가져가는 와중에 뉴스 사용료까지 내라는 건 이해불가'라고도 했다. 그런데 인공지능 학습을 위한 데이터는 또 다른 이야기 같다.
레딧의 경우도 페이스북과 유사한 소셜미디어다. 하루에도 약 6천만 명이 이용하고 있는 거대한 미디어인지라 여기에도 수많은 이야기들이 업로드되고 있다. 오픈 AI 역시 레딧의 콘텐츠를 이용한다고 하니 레딧 측이 오픈 AI에 비용을 청구하겠다고 나선 모양이다. 사실 SNS에 올라오는 뉴스, 영상, 사진, 일반 사용자들의 콘텐츠는 형태가 모두 다르다. 말하자면 일정한 규격이 없다는 의미다. 우리나라에도 메이저, 마이너 할 것 없이 정말이지 수많은 언론사가 존재한다. 같은 주제라 하더라도 서로 다른 목소리를 낸다. 그런 와중에도 '기사체'라고 할 만큼 매우 딱딱한 표현들이 가득인데 그래도 일정한 템플릿이 있는 것처럼 느껴질 정도다. 그러니 이러한 것들을 인공지능 학습의 재료로 들이붓는 것이다. 그만큼 정교화된 학습 데이터로 활용되는 셈이다. 물론 그 안에 들어가는 기사들의 팩트체크는 차치하고서라도 데이터 학습을 위해 이만한 것도 없을 것 같다. 그러니 인공지능 챗봇이든 관련 서비스든 뉴스 콘텐츠를 기반으로 학습하게 된다는 것을 알게 된다면 뉴스 콘텐츠를 생산하는 미디어 기업들이 가만히 있을까? SNS에 유통되는 콘텐츠에 대한 사용료도 받으려는 상황인데 말이다. 중요한 것은 방대한 빅데이터 사이에 뉴스 콘텐츠를 얼마나 녹였는지 세분화해서 측정할 필요가 있다. 그래야 실질적인 뉴스 콘텐츠 비용을 산정할 수 있을 테니까.
 출처 : Search Engine Journal
출처 : Search Engine Journal
인공지능이라 함은 이미 수년 전부터 4차 산업혁명이라는 키워드와 함께 꾸준하게 고도화되고 개발되었다. 정점이라는 것이 어디 있는지 모를 정도로 치솟고 있는 상황이다. 챗GPT(혹은 GPT-4), Dall-E, 미드저니 등 세상에 변화를 이끌고 있는 거대한 인공지능 플랫폼도 어쩌면 '과정'에 불과하지 않을까. 어느 지점까지 진보될지 알 수 없지만 학습데이터로서 꾸준하게 활용되는 부분에 있어 (서로의 실익만 챙기기보다) '약속과 합의'가 잘 이루어질 수 있다면 인류를 위해 더욱 큰 그림을 그릴 수 있지 않을까?




















소셜댓글