2차 전지 섹터 상장사인 LG화학과 SK이노베이션의 주식과 뉴스 데이터를 수집 후 비교 대시보드를 제작해보겠습니다.
먼저 아래 대시보드는 LG화학과 SK이노베이션의 주식 데이터는 2020년 1월 이후 데이터를 수집했고, 뉴스는 최근 뉴스를 각각 수집했습니다. 데이터 출처는 각각 네이버 금융 및 네이버 뉴스 검색 결과입니다.

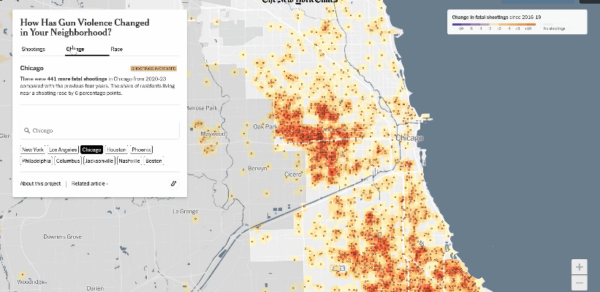
비교 대시보드를 구성하기 위해 왼쪽은 LG화학, 오른쪽은 SK이노베이션 기준으로 화면을 배치했습니다. 우선 상단에는 각 회사별 CI를 배치하고 그 사이에 대시보드 제목을 넣었습니다.
그 하단에는 2020년 1월 이후 양사의 주식 흐름을 라인 차트로 구성했고, 그 하단에는 최근 날짜 종가 기준 요약 수치를 제공합니다.
그리고 각 회사의 최근 주요 뉴스 10개 리스트를 배치하고, ‘뉴스보기’ 버튼을 클릭하면 해당 뉴스의 원본 기사 링크 페이지로 이동하도록 설정했습니다.
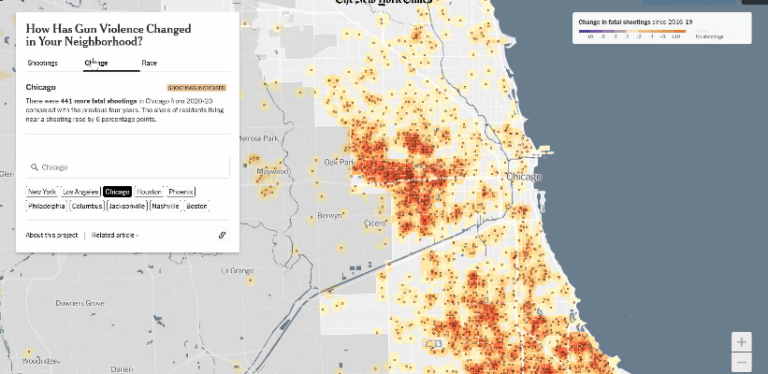
이번에는 앞선 화면을 모바일 화면 기준으로 적용했습니다.
가로 400px, 세로 600px로 설정한 다음에 수집한 뉴스링크를 연동해 ‘뉴스보기’ 버튼을 클릭하면 해당 뉴스 페이지로 이동하도록 설정했습니다. 그리고 이 화면을 조직 내 공유를 통해 임원 혹은 리더들이 이동중에도 회사 주요 뉴스를 빠르게 확인할 수 있을 것입니다.


데이터 수집 방법은 주식과 뉴스 데이터 모두 구글 스프레드시트를 활용해 수집했습니다.
우선 주식은 네이버 금융에 있는 각 종목별 시세 데이터를 가져왔습니다.
예를 들어 아래 URL 페이지에서 code 값에 나오는 6자리는 KOSPI 종목코드이며, LG화학은 ‘051910’, SK이노베이션은 ‘096770’입니다.
LG화학 https://finance.naver.com/item/sise.nhn?code=051910
SK이노 https://finance.naver.com/item/sise.nhn?code=096770
구글 시트에서 새 스프레드시트 오픈한 다음에 A1 셀에 다음과 같이 입력합니다.
=IMPORTHTML("https://finance.naver.com/item/frgn.nhn?code=051910","table",3)
IMPORTHTML = 테이블 또는 리스트 형태 웹페이지를 불러옵니다
첫 번째 “ “ 안에는 수집하려는 URL을 입력합니다.
두 번째 “ “ 안에는 테이블 형태는 “table”을, 리스트 형태는 “list”를 입력합니다.
세 번째는 해당 URL 내 table 기준으로 몇 번째인지 입력합니다.
여기에서 시세 테이블은 3번째 테이블입니다.
그리고 1페이지부터 수집하려는 페이지는 각각의 시트를 만들어 수집 후 유니온 방식으로 연결 후 데이터 시각화를 합니다.
이번에는 뉴스 데이터를 수집하겠습니다.
각 회사를 네이버에서 검색 후 발생하는 쿼리를 기준으로 해당하는 URL을 입력 후 수집하고자 합니다. 새 스프레드시트를 열어 A1 셀에 아래와 같이 입력합니다.
query에 해당하는 부분이 찾고자 하는 검색 쿼리이기 때문에 LG화학 대신 SK이노베이션으로 수집하고자 하면 해당 query를 변경하시면 됩니다.
=IMPORTXML("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=LG%ED%99%94%ED%95%99","//div[3]/ul/li/div/div")
이전 주식 데이터와 달리 IMPORTXML로 입력하는 이유는 단순히 테이블을 수집하는 것이 아니라 웹 페이지 내 특정한 영역만 골라서 가져오기 위해 IMPROTXML을 활용했습니다.
필자는 데이터 시각화 전문 기업 BigxData에서 데이터 시각적 분석 전문가로 활동하면서, 데이터에 스토리텔링을 입히는 일을 주로 하고 있습니다. 저서로는 ‘데이터 시각적 분석 태블로로 끝내기’, ‘태블로 굿모닝 굿애프터눈’이 있습니다. 저자가 운영하는 유튜브 채널 (http://bit.ly/YT_MDV)에서 만날 수 있습니다.