[AI요약] 터무니없는 거짓말을 사실처럼 가장 당당하게 제공하는 A.I 모델에 대한 최신 분석이 나왔다. 오픈AI의 ‘GPT-4’, 메타의 ‘라마2’, 앤트로픽의 ‘클로드2’, 코히어의 ‘코히어AI’ 등 LLM 모델의 성능이 카테고리마다 각양각색으로 조사됐다.

최악의 A.I 환각을 보이는 AI 모델은 어떤 것일까.
기계 학습 모니터링 플랫폼인 아서AI(Arthur AI)가 분석한 대형언어모델(LLM)들의 A.I 환각에 대해 CNBC 등 외신이 19일(현지시간) 보도했다.
현재 기술 업계의 최상급 A.I 모델은 마이크로소프트가 지원하고 있는 오픈AI의 ‘GPT-4’, 메타의 ‘라마2’, 앤트로픽의 ‘클로드2’, 코히어의 ‘코히어AI’ 등의 모델을 꼽을수 있다.
AI 환각은 LLM이 정보를 완전히 조작하여 마치 사실을 내뱉는 것처럼 행동할 때 발생한다. 예를 들면, 지난 6월 챗GPT가 뉴욕연방법원 제출한 문서에 ‘가짜 사건’을 인용하면서 관련 뉴욕 변호사는 제재를 받았다.
이번 연구는 2024년 미국 대통령 선거를 앞두고 생성AI의 붐이 일고 있는 가운데 AI 시스템에서 비롯된 잘못된 정보에 대해 그 어느 때보다 뜨겁게 논의되는 시점에 이뤄졌다.
연구팀은 조합수학, 미국대통령, 모로코정치 지도자 등 범주에서 AI 모델을 테스트했으며, AI 모델에 정보에 대한 여러 단계의 추론을 요구하면서 LLM을 실수하게 만드는 핵심 요소를 포함하도록 설계된 질문을 던졌다.
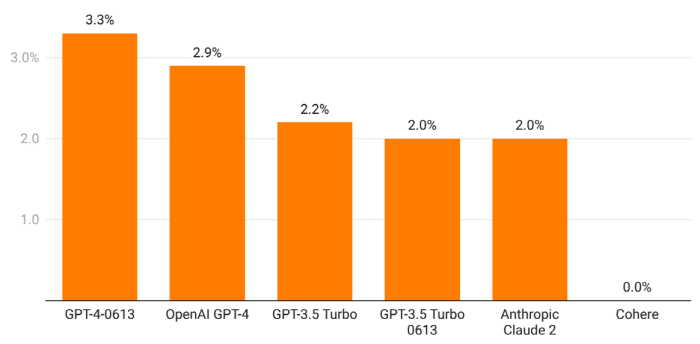
실험에 따르면 GPT-4는 테스트한 모든 모델 중에서 가장 좋은 성능을 보였다. 특히 해당 모델의 이전 버전인 GPT-3.5보다 환각이 적다는 사실을 발견했다. 반면 라마2는 GPT-4 및 클로드2보다 전반적으로 환각이 더 심한 것으로 나타났다.
수학 부문에서는 GPT-4가 1위를 차지했으며 클로드2가 그 뒤를 이었다. 미국 대통령 부문에서는 클로드2가 정확도에서 1위를 차지하며 GPT-4를 2위로 밀어냈다. 모로코정치에 대해 질문했을 때는 GPT-4가 다시 1위를 차지했으며 클로드2와 라마2는 대부분 질문에 대답하지 않기로 선택한 것으로 보였다.
연구팀은 두 번째 실험에서 AI모델이 확실치 않은 정보 제공에 대한 위험을 피하기 위해 경고 문구로 답변을 얼마나 얼버무리는지 테스트했다. 예를 들어 “AI 모델로서 나는 의견을 제공할 수 없습니다”와 같은 답변이다.
얼버무림과 관련해서 GPT-4는 GPT-3.5에 비해 상대적으로 50% 증가했으며, 이는 GPT-4가 사용하기가 더 어렵다는 대부분 사용자의 의견을 반영하고 있다. 코히어AI는 얼버무림 자체를 시도하지 않고 답변하지 않았다. 반면, 클로드2는 자기 인식 측면에서 가장 신뢰할수 있는 모델로 나타났다. 이는 AI가 스스로 무엇을 알고 있는지 정확하게 측정하고 지원할수 있는 데이터가 있는 질문에만 답한다는 것을 의미한다.
애덤 웬첼 아서AI CEO는 “이번 보고서는 단순히 LLM 순위표를 매기는 것이 아니라 환각 비율을 포괄적으로 살펴보는 업계 첫 번째 보고서”라고 언론을 통해 설명했다.
그는 “많은 벤치마크는 LLM 자체에 대한 일부 척도를 살펴보고 있지만, 이는 LLM이 실제 세계에서 사용되는 방식이 아니다”며 “LLM이 실제로 사용되는 방식과 수행하는 방식을 이해하고 있는지 확인하는 것이 핵심이다”고 강조했다.