
산업 각 분야에서 초거대언어모델(LLM, Large Language Model)을 활용한 기술과 서비스가 앞다퉈 등장하고 있다. 과연 LLM의 강점과 한계는 무엇일까? 그리고 여러 분야 중 특히 교육 분야에 미칠 영향은 어떨까?
30일 LLM을 둘러싼 다양한 질문을 가지고 관련 업계 전문가, 기업인들과 함께 소통하는 ‘테크 이지 토크(Tech easy talk)’ 첫 번째 행사가 연세대학교 캠퍼스에서 열렸다.
오후 3시부터 진행된 첫 번째 ‘테크 이지 토크’ 주제는 ‘LLM의 미래: 신뢰할 수 있는 대형언어모델(LLM)과 교육에 가져올 변화의 바람’이다.

이번 행사 패널로는 송경우 연세대학교 응용통계학과 교수, 최호식 시립대학교 도시빅데이터융합학과 교수가 나섰다.
송 교수는 카이스트 산업공학 박사 출신으로 네이버 클로바 방문연구원, 시립대 인공지능학과 조교수를 거쳐 현재 연세대학교 응용통계학과와 통계데이터사이언스학과 조교수로 근무하고 있다. 최근 3년간 NeurIPS, ICML, AAAI, KDD, CVPR 등 AI 탑 컨퍼런스에 12편의 논문을 게재하며 주목을 받고 있다. 현재는 에듀테크 기업 북아이피스와 산학협력 프로젝트를 진행하는 한편, 자체 교육 특화 대형언어모델을 개발하며 교육 분야의 LLM(거대언어모델) 접목을 시도하고 있다.

최호식 교수의 경우는 서울대 통계학 박사 출신으로 호서대와 경기대를 거쳐 현재는 서울시립대학교 도시과학빅데이터AI연구원 개인정보보호센터장과 한국자료분석학회 학술위원장을 비롯해 일반대학원 도시빅데이터융합학과와 인공지능학과 교수로 근무하고 있다. 특히 최 교수는 교육콘텐츠 IP 라이선싱 플랫폼 고도화를 위한 컴포넌트 단위 콘텐츠 관계성 분석 AI 기술 과제를 비롯해 다양한 산학협력, 정부 과제를 수행 중이다.

이날 ‘개인정보보호가 가능한 상황 내 LLM 활용 학습방법’을 주제로 발표에 나선 최 교수는 “최근 LLM은 산업적으로 광범위하게 활용되고 있지만, 사실 프라이버시 이슈가 있다”며 “익명화 가명화한 프롬프트 적용, 암호화 방안에 대해 연구 중”이라고 운을 뗐다.
“어떤 문제가 주어지면 그 문제에 대한 독창성을 누가 보호할 것인가의 문제가 생깁니다. 가령 학원에서 출제한 문제가 있다면, 이를 접한 사람들을 통해 문제가 재생산될 수 있죠. 원작자의 고유한 참신성이 다듬어 지면서 좋은 문제로 발전할 수 있지만, 그 고유한 아이디어는 귄리를 보호받지 못한다는 생각이 듭니다. 그래서 이런 문제가 들어오면 현재 트랜스포머 등 굉장히 다양하게 개발된 기술을 통해 문장들을 백터 형태로 표현하고 암호화하는 원리 입니다.”
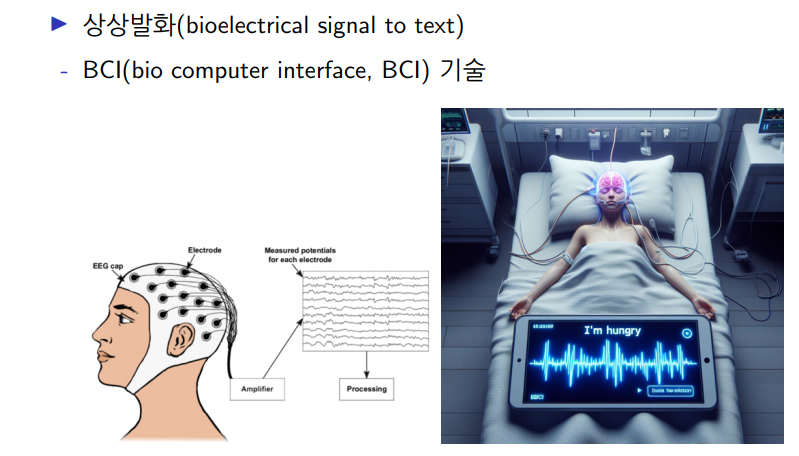
이어 최 교수는 다양한 프롬프트 예제를 통해 연구 내용을 설명하는 한편, 인컨텍스트 러닝을 신호 데이터에 적용하는 연구 내용에 대헤서도 소개하는 시간을 가졌다. 이는 사람의 뇌파 신호 측정을 통해 텍스트로 전송하는 기술로 ‘상상 발화(bioelectrical signal to text)’라 불리는 BCI(bio computer interface, BCI) 기술이다. 최 교수는 “이 기술 역시 프라이버시 이슈가 있다”며 최근 연구 동향을 설명하기도 했다.
‘신뢰가능한 대형언어모델을 위한 최근 기술 동향 소개 및 교육 컨텐츠 분석’을 주제로 두 번째 발표에 나선 송경우 교수는 “시립대 학생들과 최호식 교수님, 연세대 학생들이 함께한 연구”라고 소개하며 말을 이어갔다.
이날 송 교수는 대형언어모델의 원리와 최근 활용 분야에 대한 동향을 간단하게 언급한 후 ‘대형언어모델 기반 Document 질의응답’ ‘대형언어모델과 교육컨텐츠 관계 분석’ ‘자체 교육 특화 대형언어모델 개발’ 등의 내용으로 발표를 진행했다.
특히 '대형언어모델 기반 Document 질의응답’ 파트에서 송 교수는 “문서에 기반해 LLM이 답 해주기를 원하는 것”이라며 “한번에 요청을 하는 것이 아닌 스텝 바이 스텝으로 요청을 하게 된다”고 설명하며 전체 방법론을 소개했다.

이는 질문과 문서의 유사도를 측정하는 ‘TF-IDF’를 시작으로 각 LLM 요청 단계를 통해 진행된다. 이 각각의 단계는 질문과 문단의 관련 여부를 판단하는 ‘Associative Selection’을 거쳐 다시 문단이 질문에 답 가능 여부를 판단하고 가능할 시 근거를 생성하는 ‘Rationale Generation’로 이어진다. ‘Systematic Composition’는 앞선 결과를 토대로 종합적인 답을 도출하는 과정이다.
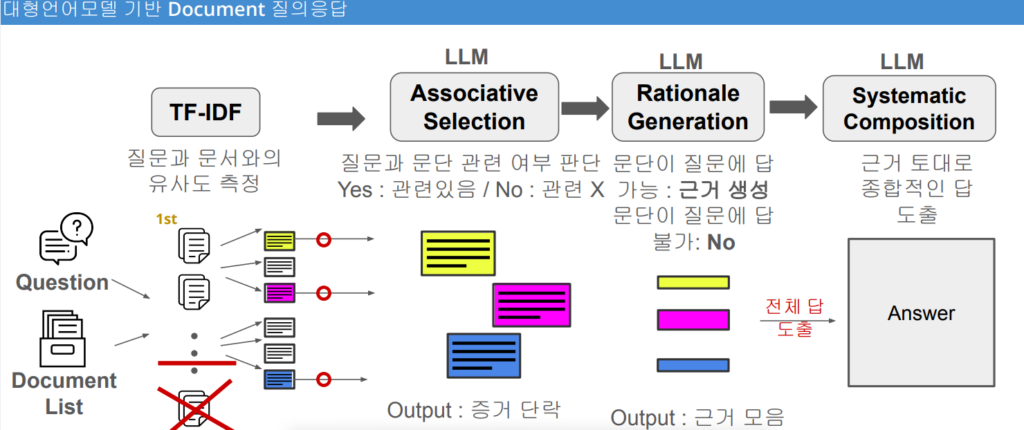
“일단 질문이 들어오면 그 질문에 있는 키워드와 도큐먼트는 굉장히 길겠죠. 그러면 수백 페이지의 도큐먼트에서 그 키워드와 관련이 있는 파트만 가져오게 됩니다. 다음으로는 물어보는 거죠. 여기까지는 아직 언어모델은 아니지만, ‘TF-IDF’를 통해 과거에 많이 쓰였던 키워드 기반으로 질문의 키워드, 문서의 키워드를 비교하고 1차로 필터링을 하는 과정입니다. 다음으로 LLM에게 ‘GPT야 너도 그렇게 생각해’라고 물어보는 거예요. 이후에는 언어모델이 ‘Yes’라고 답한 것만 가져와서 왜 그렇게 말한 것인지 근거를 물어보고 그 근거를 토대로 최종적인 질문에 대한 답을 다시 요청하는 겁니다.”
한편 이날 송 교수는 대형언어모델을 통한 학습자료와 교과 자료 관계성을 분석하는 연구 소개와 함께 메타의 라마 3(LlaMA 3)를 기반으로 개발한 ‘라마3-에듀(LlaMa3-Edu)’를 소개하기도 했다.

“GPT-4 옴니의 경우 딱 결과문만 제시하고 각 결과물의 토큰에 대한 확률값을 굉장히 제한적으로 보여주는 등의 제약이 있기 때문에 자체적인 교육 특화 대형언어모델을 만드는 것이 필요하다고 생각했습니다. 때 마침 약 80억개정도의 파라미터를 가지고 있는 ‘라마3’가 공개됐죠. 특별한 경우 외에 상업적으로도 이용이 가능한 모델이라는 장점도 있었고요. 또 이를 잘 트레이닝 시켜 GPT-4와 유사한 정도의 성능을 내도록하는 라마3 변형 모델들이 공개되기도 했죠. 저희 역시 이와 유사하게 라마 3를 가져와 교육 콘텐츠의 데이터에 대해 추가 학습을 시키면 특정 테스크에서는 GPT-4에 버금갈 수 있는 모델을 만들 수 있을 것이라고 판단했습니다. 그리고 북아이피스, 시립대와 함께 만든 데이터베이스를 이용해 insturction data를 만들었습니다. 쉽게 말해 라마 3를 추가 학습 시키기 위한 데이터를 만든 것이죠. 현재는 기존 라마 3보다 정말 성능이 좋은 것인지 검증을 하고 있는 상황입니다.”
송 교수에 따르면 이 ‘라마3-에듀’는 특정 교육 콘텐츠(문제)에 대해 질문 유형을 파악하고 바른 조합을 찾아 문제 요지를 파악하는 결과를 내고 있다. 또 문장의 흐름을 이해해 정답을 도출하는 결과도 얻은 상황이다.
이날 발표 이후 진행된 ‘네트워킹’ 시간에는 두 교수의 발표 내용과 관련해 LLM 기술 기반 비즈니스를 고민하는 기업 관계자를 비롯해 참석자들의 질문이 이어지며 열기를 더해갔다.
한편 이날 ‘테크 이지 토크’에 함께한 북아이피스 윤미선 대표는 “교육 분야의 AI 활용이 주로 학습 데이터 분석에 몰려있는데, 분석 결과에 따라 필요한 교육콘텐츠를 골라 쓸 수 없다면 맞춤 교육이 될 수 없다"며 "오늘 발표한 교육 특화 자체 대형언어모델을 쏠북에 빨리 적용해 맞춤 교육에 최적화한 교육콘텐츠 거래 서비스를 구현하고 싶다”고 소감을 밝혔다.



















