한국언론진흥재단은 ‘언론사를 위한 언어정보 자원 개발’ 사업의 결과물인 ‘KPF-BERT’를 23일 공개했다.
‘KPF-BERT’는 구글에서 개발한 다국어 언어모델인 ‘BERT(Bidirectional Encoder Representations from Transformers)’를 한국언론진흥재단이 보유한 빅카인즈 기사 데이터를 활용해 학습시킨 결과물이다. 구글이 2018년 발표한 ‘BERT’는 앞의 단어들을 참조해 다음에 나올 단어를 예측하는 방식이었던 기존의 단방향 언어 모델과 달리 문장에서 예측해야 할 단어 이후의 단어들까지 양방향으로 참조해 그 의미를 더욱 잘 이해하는 방식으로 학습돼 인공지능과 자연어 처리 분야에서 획기적 기술 개선을 이루어냈다.
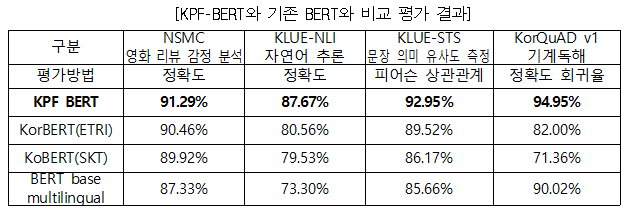
인공지능을 활용한 뉴스 추천배열, 자동작성, 요약, 댓글관리, 오탈자 및 비문 교정, 비슷한 주제 기사 묶기, 외신 자동 번역 등 언론 영역에서 인공지능 기술의 도입 및 적용 필요성이 증가하고 있지만, 언론사 자체적인 기술 개발은 여러 가지 이유로 인해 어려운 상황이다. ‘KPF-BERT’는 재단이 보유한 2000년부터 2021년 8월까지 빅카인즈 기사 약4,0000만 건(20년치 8,158만 건 중 1차 정제 후 약 4,000만 건)을 학습해 언론사 및 뉴스 기사 활용 기술에 최적화되도록 개선했다.
‘KPF-BERT’ 구축 내용과 활용을 위한 안내 내용은 한국언론진흥재단 깃허브(https://github.com/KPFBERT/)에 모두 공개돼 있다.
이번에 공개된 ‘KPF-BERT’를 활용하면 단순 맞춤법 검사를 넘어 문맥과 의미를 고려한 맞춤법 검사기, 입력하는 연속된 문장에서 해당 시점에 가장 적절한 단어를 추천하는 단어 자동완성 모델, 1차 완성된 기사에서 문장 간 또는 문장 내 어울리지 않는 표현이나 어휘는 물론 문법적 오류 검출, 뉴스 댓글 등에서의 혐오 표현을 검출하고 순화해 표현하는 모델, 관심 사안에 대한 기사의 긍정·부정 등의 논조 파악 모델, 협찬기사 및 정보 전달을 가장한 광고 등의 광고성 기사 검출 모델 등의 개발을 기대할 수 있다.


















소셜댓글