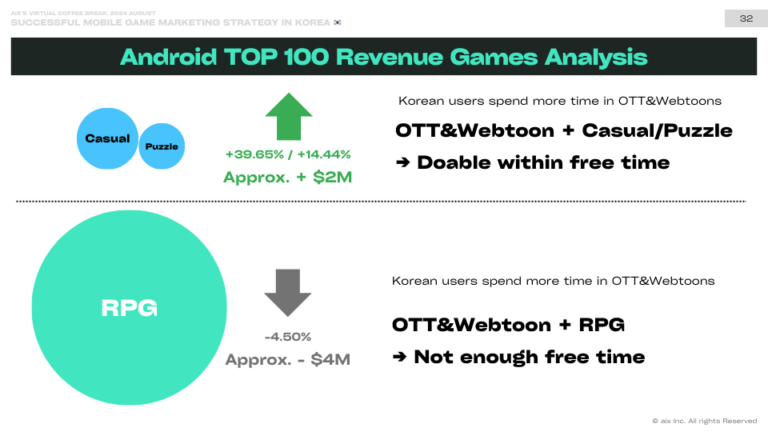
구글이 네트워크온칩(NoC) 기술 업체인 프로비노 테크놀로지(Provino Technologies)를 인수했다고 IEEE스펙트럼이 최근 보도했다. NoC는 칩 안에서 통신 네트워크를 구현하는 프로세서다.
실리콘밸리에 본사를 둔 프로비노 테크놀로지의 신기술은 인공지능(AI) 처리를 위한 보다 빠르고 효율적인 프로세서를 약속하는 기술로 알려져 있다.

구글은 프로비노 인수에 대한 언급 요청에도 자세한 내용을 밝히지 않았다. 그러나 이번 프로비노 인수는 구글 내부 AI용으로 NoC 기술을 본격 채택하려는 신호탄으로 여겨진다.
구글은 이미 지난 2월 초 프로비노로부터 NoC 통신과 전력 관리를 위한 특허 및 출원특허 20건을 미공개 금액으로 사들였다. 이는 프로비노의 전체 지재권 포트폴리오로 보인다.
비슷한 시기에 프로비노는 웹사이트를 폐쇄했고, 제2 사무소가 있는 인도 아흐메다바드 사무소의 프로비노 엔지니어들은 자신들이 구글에서 일하는 사람이라고 말하기 시작했다. 프로비노는 인수에 대한 언급 요청에 응하지는 않았지만 구글은 IEEE스펙트럼에 프로비노를 인수했다고 확인했다.
프로비노는 전직 애플 엔지니어인 샤일렌드라 데사이가 지난 2015년 실리콘밸리 산타클라라에서 창업한 회사로서 NoC를 개발하기 위한 아이패브릭(iFabri)이라는 플랫폼(아키텍처)을 제공한다.
구글은 NoC 기술로 퍼블릭 클라우드 컴퓨팅 인프라에서 단일 칩 멀티프로세서 리소스를 공유하는 여러 명의 동시 사용자를 지원할 수 있다. 또한 QoS(Quality of Service)를 지원할 수도 있다. NoC 기술로 AI 처리량, 종단 간 지연, 공정성 및 마감 시간 측면의 다양한 요구 사항을 충족하고 해결하려 할 것이라는 의미다.
기존 컴퓨팅용 SoC에서 통신으로 한걸음 더 나아간 NoC
구글이 왜 이 업체를 사들였는지 알려면 NoC 기술과 그 장점을 살펴봐야 한다.
네트워크 온 칩(NoC)은 기존 컴퓨터 네트워킹의 이론과 방법을 칩 상의 통신 네트워크로 구현한 것이다. 즉, NoC는 집적 회로(IC)에 구현한 네트워크 기반의 통신 서브시스템이다. 시스템 온칩(SoC) 시스템에 있는 모듈들 사이에 위치한다. 이 모듈들은 컴퓨터 시스템의 다양한 기능을 네트워킹 관점에서 조직적으로 배열한 반도체 IP 코어다. 이렇게 해서 NoC는 SoC 모듈들 간에 라우터 기반 패킷 교환 네트워킹을 구성하게 된다.
최신 인공지능(AI)용 프로세서에는 수천 개, 심지어 수십만 개의 코어가 상주하게 되며, 각각의 코어는 방대한 양의 데이터를 이동시켜야 한다. NoC 기술은 데이터 패킷을 보내는 라우터에 기반해 수백개, 수천개의 코어를 가진 ‘다중 코어’ 칩의 통신을 가속화한다.

프로비노의 NoC 기술은 집중적 계산 위주로 설계된 기존 컴퓨팅 프로세서와 달리 분산형 아키텍처를 사용했다. 따라서 여러 작업을 병렬로 실행하고 동시에 서로 통신할 수 있어 성능과 통신 처리량을 개선하며 전송선도 짧아진다. 자연히 기존의 버스와 크로스바 통신 아키텍처에 비해 주목할 만한 개선을 보여준다. 즉, 다른 서브 통신 시스템 설계에 비해 SoC의 확장성과 전력 효율성 향상을 가져다 준다.
전통적 집적회로(IC)는 각 신호마다 하나의 선을 사용해 전용 포인트 대 포인트(point to point) 연결로 설계되면서 네트워크가 조밀해진다. 특히 대형 설계시 물리적으로 회로에 더 많은 캐패시턴스, 저항 및 인덕턴스가 발생하는 한계를 맞게 된다. 반면 NoC는 통신 서브 시스템에서 상호 연결의 인접성과 희소성을 제공함으로써 기존의 버스 기반 및 크로스바 기반 시스템의 한계를 극복할 수 있게 해준다.
여러 작업 병렬 실행에 동시 통신···가장 효율적인 신경망용 아키텍처
이에 따라 프로비노의 분산형 NoC 아키텍처들은 기존 칩에 비해 속도가 빠르고 데이터 병목 현상이 덜할 뿐 아니라 본질적으로 확장성이 뛰어나고 재구성 가능하며 고장방지 기능까지 갖추게 된다.

므드 파하두 레자 센트럴 미주리 대학 컴퓨터과학과 조교수는 “통신을 위한 기술은 단순히 (집중적인) 계산만을 위한 방식으로는 향상되지는 않는다”며 “NoC의 분산형 아키텍처는 애플리케이션이 여러 작업을 병렬로 실행하고 동시에 서로 통신하도록 할 수 있다. 따라서 성능이 개선되고 처리량이 향상되며 전송선이 짧아진다”고 설명했다.
특히 신경망은 ‘뉴런’과 메모리 사이의 빈번한 통신에 의존하는 훈련을 위해 작동할 때 집약적 계산을 수행하는 것으로 유명하다.
레자 교수는 “두 노드 사이에는 여러 경로가 있기 때문에 하나의 링크가 중단되더라도 패킷을 다른 방식 경로를 찾아 패킷을 보낼 수 있다”며 “이것은 신경망을 위한 가장 효율적 아키텍처가 되게 한다”고 설명했다.
구글은 2015년부터 신경망을 위한 독자적 주문형 반도체(ASIC) 개발을 시작했다. 텐서 프로세싱 유닛(Tensor Processing Unit·TPU)으로 불리는 이 하드웨어(HW)는 구글의 클라우드 데이터 센터 내에 배치돼 AI서비스를 이용해 머신러닝(기계학습)을 실행하도록 지원한다. 즉,번역, 사진, 검색, 음성비서 및 지메일 같은 AI 제품에 동력을 공급한다.
구글의 일부 연구원들은 지난 수년 동안 NoC 기술을 연구해 왔지만 구글 TPU의 정확한 사양은 알려지지 않았다.
구글, 프로비노 인수계기로 NoC본격 채택 시동거나
레자 교수는 “NoC로의 대규모 전환은 하룻밤 새 일어날 것 같지 않다”며 “아키텍처와 알고리즘 측면에서 여전히 많은 과제가 있다”고 말한다. NoC의 핵심은 라우팅이며 라우터 설계 방법, 사용하는 알고리즘, 버퍼 및 링크 용량에 대한 많은 궁금증이 있다”고 말했다.
그럼에도 불구하고 특히 구글이 운영하는 규모의 머신 러닝 시스템의 효율성을 개선하고 엄청난 전력 사용량 저감을 약속하는 어떤 것이라도 지속 가능한 AI의 미래에 좋은 일이 될 수 밖에 없다.
구글의 프로비노 인수로 새로이 주목받고 있는 NoC 기술은 매니코어(수백 수천개의 코어) 컴퓨터 아키텍처들이 보편화됨에 따라 커다란 성장세를 보일 것으로 예상되고 있다.
시판중인 PC에 사용되는 일반적인 NoC로 그래픽칩(GPU)을 꼽을 수 있다. GPU는 일반적으로 컴퓨터 그래픽, 비디오 게임, AI 가속용으로 사용된다.