데이터의 의미를 왜곡하지 않는 방법
‘데이터 시각화의 재구성’은 기사나 뉴스레터 등에서 볼 수 있는 잘못된 데이터 시각화 사례를 바탕으로 만드는 콘텐츠입니다. 기존 데이터 시각화의 잘못된 점을 살펴보고 올바른 데이터 시각화 차트를 제작하기 위해 고민하였습니다. 차트를 만드는 사람에 따라 디자인이 조금씩 달라질 수는 있지만, 데이터의 의미를 정확하게 전달하기 위해 지켜야 할 요소를 적용하여 재구성하였음을 알려드립니다.
‘데이터 시각화의 재구성’의 주제를 이야기하기 전에 한 가지 질문을 드릴게요. 아래에 보이는 데이터 시각화는 건강보험심사평가원에서 발표한 2020 급여의약품 청구 현황 보고서에 삽입된 차트입니다. 다른 차트와 차이점을 찾아보세요! 다른 점을 발견하셨나요? 어떤 점이 눈에 띄셨나요?
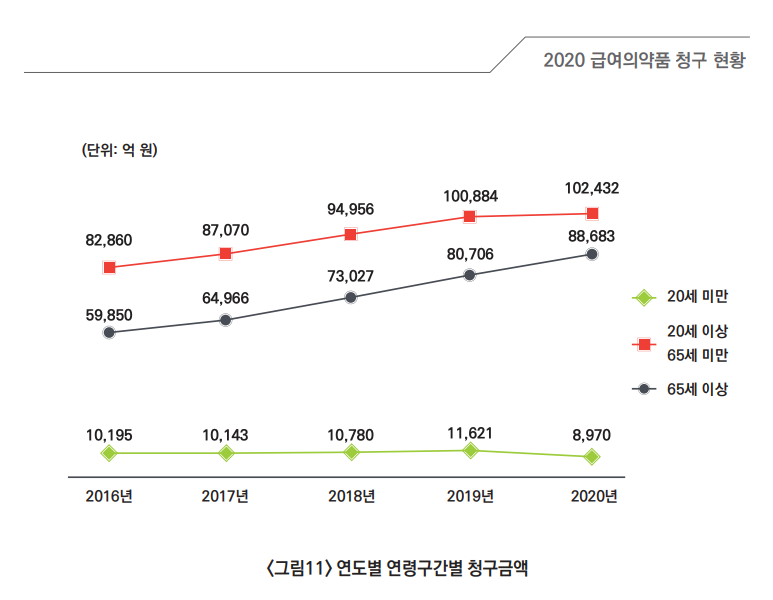
정답은 ‘y축이 없는 차트’입니다. 다양한 데이터 시각화 가운데 우리는 종종 이 차트처럼 y축이 보이지 않는 차트를 마주하곤 하는데요, 언뜻 보기에는 y축이 없어도 데이터의 의미를 읽고 이해하는 데 큰 문제가 없어 보이죠? 정말 y축이 없어도 괜찮은 걸까요?
이번 ‘데이터 시각화의 재구성’은 y축이 없는 차트에 관해 이야기해보려고 합니다. 기사에 삽입된 데이터 시각화 사례를 통해 y축의 역할이 무엇인지, 차근차근 살펴보겠습니다.
국민지원금 이의신청, 정말 그렇게 많았을까?
먼저 A일보의 사례를 살펴보겠습니다. 이 데이터 시각화는 국민지원금 이의신청 추이를 나타내고 있는데요, 차트를 보면 국민지원금 신청 첫날인 9월 6일부터 급격히 치솟았다가 9월 9일이 되자 차츰 떨어지는 모양새입니다
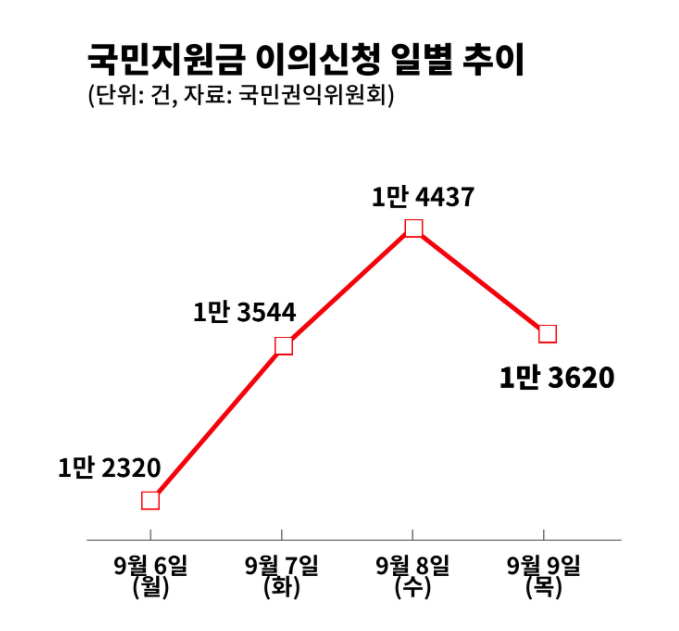
이 차트만 두고 보면 가장 아래쪽의 9월 6일(월) 데이터와 가장 위쪽의 9월 8일(수) 데이터가 엄청난 차이를 나타내는 것처럼 보여요. 이의신청 건수가 폭발적으로 늘어난 것처럼 느껴지기도 하고요. 과연 그럴까요?
같은 데이터를 가지고 라인차트를 다시 그려 보았습니다. 위의 차트와 다른 점은 딱 하나, 0부터 시작하는 y축이 있다는 것입니다.
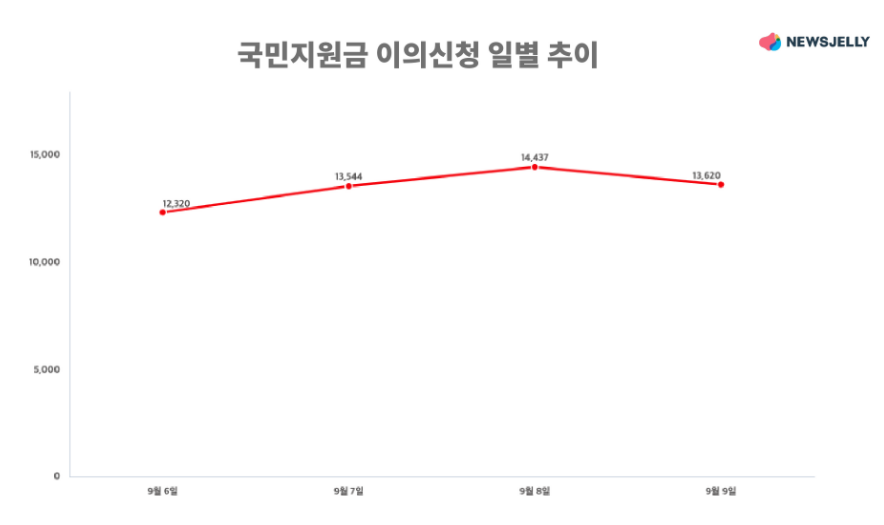
y축을 남겨둔 차트를 보니 경사각이 완만해졌습니다. 재구성한 차트를 보면 이의신청 건수가 폭발적으로 증가한 것은 아니고 계속해서 비교적 비슷한 추이를 보이고 있다는 사실을 알 수 있습니다.
같은 데이터지만 차트의 경사각에 따라 전혀 다른 느낌을 받을 수 있는데요, 데이터를 왜곡한 것은 아니지만 과장된 측면이 있어 보입니다.
서울 지역 평균 전세금은 급등했을까?
다음 사례는 서울 빌라 지하층의 평균 전세금 추이를 나타내는 데이터 시각화입니다. B일보에서 발행한 기사에 삽입된 이 라인차트 역시 엄청난 상승세를 보이고 있어요.
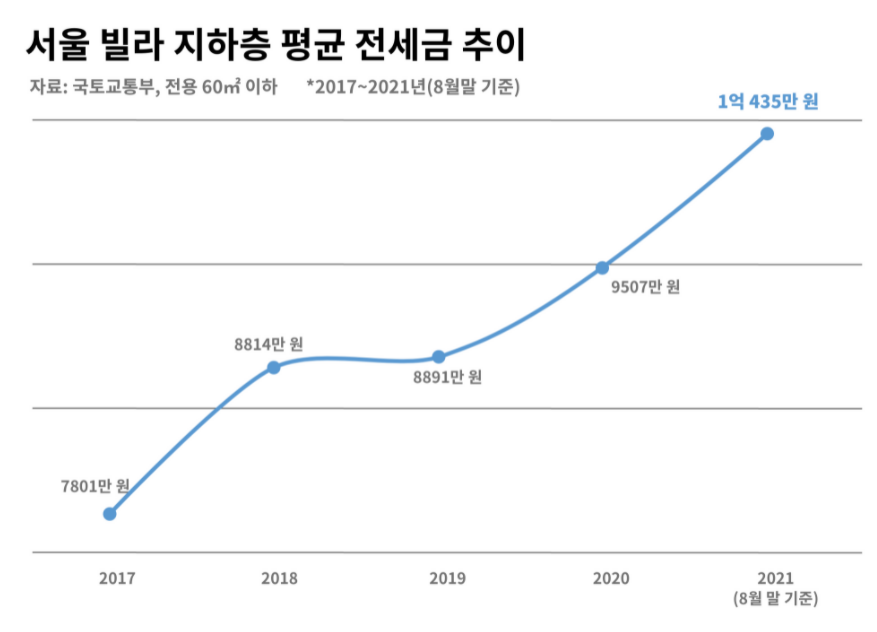
해당 차트를 보면 2017년 데이터는 x축에 가까이 놓여 있습니다. 2021년 데이터는 가장 위쪽 그리드에 가깝고요. 라인만 본다면 마치 2017년은 거의 0부터 시작되고 2021년에는 어마어마한 높이로 치솟았다고 생각할 수 있어요.
이 차트도 다시 그려볼까요? y축을 남겨두면 라인의 각도가 확연히 달라집니다. 상승세를 보이고 있기는 하나 앞선 차트와 느낌이 크게 다릅니다.
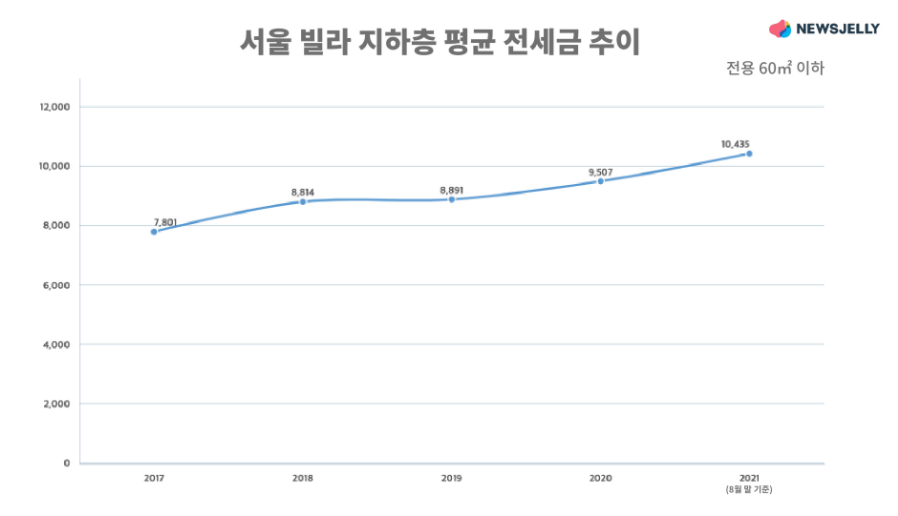
0부터 시작하는 y축을 남겨두니 차트의 라인이 완만한 상승세를 보입니다. 전세금이 천정부지로 치솟은 것 같은 느낌을 주는 기존 데이터 시각화와 달리 경사각이 작아지니 그리 많이 오른 것처럼 느껴지지는 않습니다.
y축을 삭제하고 경사각을 크게 만든 것은 ‘2017년에서 2021년까지 전세금이 많이 올랐다’는 내용을 전달하기 위한 장치로 보입니다. 제작자의 의도를 강조하기 위해서 말이죠.
여러분은 어떻게 생각하시나요? B일보에 삽입된 차트는 데이터의 의미를 과장한 것일까요? 아니면 단순히 강조한 수준으로 이해해야할까요?
카카오 계열사는 폭증했을까?
C일보에서 발행한 기사에 삽입된 사례도 마찬가지입니다. 카카오의 국내 계열사 추이를 나타내는 데이터 시각화인데요, 이 차트만 보면 계열사의 수가 급격하게 늘어난 것 같아요.
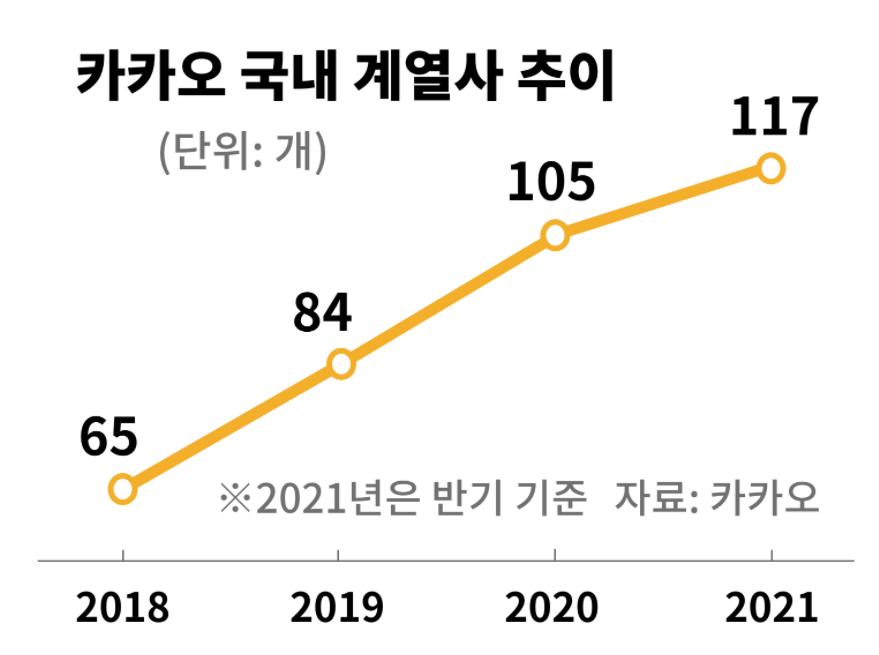
이 데이터 시각화는 앞서 본 사례처럼 2018년 데이터가 x축에 가까워요. 그래서 0부터 시작하는 듯한 인상을 주고 실제 데이터가 증가한 것보다 증가폭이 훨씬 크게 느껴집니다.
이 차트도 0부터 시작하는 y축을 남겨두면 라인의 각도가 달라집니다. 데이터를 자세히 보면 매년 20여 개 안팎의 계열사가 늘어났다는 사실을 알 수 있습니다.
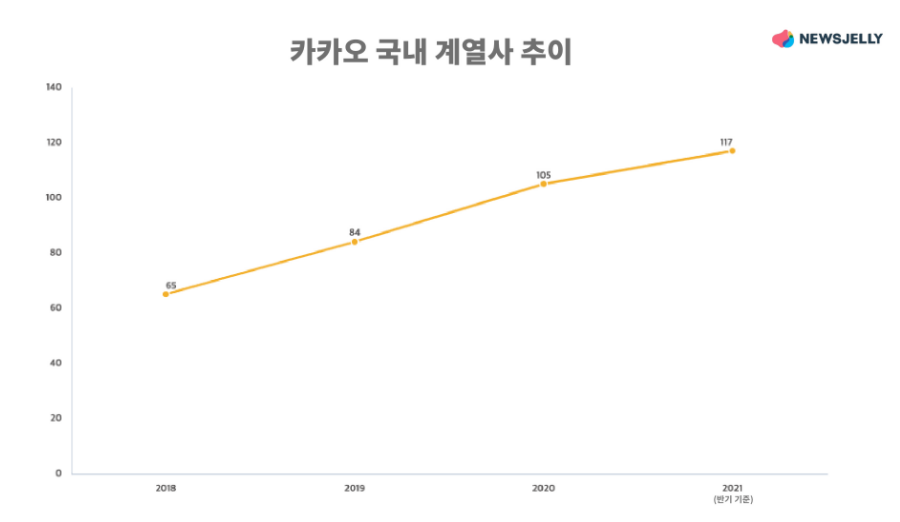
재구성한 차트입니다 (데이터: 카카오, 제작: DAISY Basic)
재구성한 차트를 보면 카카오의 국내 계열사 추이는 상승세를 보이고 있지만, C일보에 삽입된 차트처럼 바닥에서 시작하여 천장까지 치솟은 듯한 느낌을 주지는 않습니다. 차트 제작자는 ‘계열사가 폭발적으로 증가하여 문제’라는 의미를 담은 것으로 보입니다. 그러나 한 해에 몇군데가 늘어나야 ‘많이’ 늘어난 걸까요? 저마다 기준이 다를텐데요, 앞선 사례와 마찬가지로 데이터 시각화 제작자의 과장된 의도가 담겨 있다고 볼 수 있지 않을까요?
y축 유무에 따라 달라지는 데이터의 의미
지금까지 y축 유무에 따라 데이터의 의미를 다르게 받아들이는 사례를 살펴보았습니다. 여러분은 어떻게 보셨나요? 경사각에 따라 달라지는 차이를 느끼셨나요?
데이터 시각화는 데이터의 의미를 쉽게 전달하는 매개이지만 이를 그대로 받아들여서는 안 됩니다. 데이터 시각화를 어떻게 하느냐에 따라 왜곡된 의미를 전할 수도 있거든요.
특히 y축이 아예 없는 차트는 잘못된 의미를 전달하기가 쉬운데요, 로우 데이터(Raw Data)를 조작하는 것은 아니지만 시각적 요인으로 인한 인지적 오류가 생길 가능성이 있습니다. 즉, 사용자가 데이터를 해석하는 과정에서 데이터가 가진 본래의 의미를 받아들이는 것이 아니라 데이터 시각화를 만든 사람의 의도에 영향을 받을 수도 있다는 것이죠.
우리가 데이터를 시각화하는 이유는 데이터의 의미를 쉽게 전달하기 위해서 입니다. 그 과정에서 오해의 소지가 있어서는 안됩니다. 데이터를 시각화할 때, 데이터를 시각화한 자료를 볼 때 한 번 더 고민하는 자세가 필요합니다. 시각화를 제작하는 사람에 따라 얼마든지 의미를 왜곡할 여지를 남겨둘 수 있거든요.
오해의 소지 없이 데이터의 의미를 잘 전달할 수 있는 시각화를 만드는 것도 중요하지만 이와 더불어 사용자의 데이터 해석 능력 또한 중요하다고 할 수 있겠습니다.
데이터와 데이터 시각화에 관해 궁금한 사항이 있거나, 잘못된 시각화 사례를 발견하셨다면 언제든 뉴스젤리에 알려주세요. 여러분의 적극적인 피드백을 기다리고 있겠습니다. 우리 다음 콘텐츠에서 또 만나요!


















소셜댓글