안녕하세요, 뉴스젤리 개발팀 주젤리입니다. 이번 콘텐츠에서는 패션에 관심이 많은 한 직원분의 불평을 듣고 시작한 데이터 분석 프로젝트를 소개하려고 합니다. 불평의 원인은 온라인 쇼핑할 때 브랜드마다 알맞은 사이즈를 고르기 어렵다는 것이었는데요. 패션에 관심이 없는 저는 의류 사이즈에 통일화된 규격이 있을지부터 궁금했고, 이러한 궁금증이 꼬리에 꼬리를 물기 시작했습니다. 그래서 결국 데이터까지 수집해 의류 사이즈에 대한 심도 있는 분석을 하게 된 이야기를 소개합니다.
………
우선 의류 사이즈 규격에 대해 찾아보니 만 18세 이상 성인의 의류 사이즈에 대한 규정이 있습니다. 국가기술표준원에서 규정한 ‘KS 의류 치수 규격’인데요. 의류 치수는 ‘피트성’에 따라 크게 2가지 방법으로 표기해야 합니다. 옷의 ‘피트성’이란 신체 치수에 의류 치수가 맞는 정도입니다. 피트성이 필요한 의류는 정확한 숫자로, 피트성이 필요하지 않은 의류는 범위를 나타내는 호칭으로 표기합니다. 정장은 100-85-170으로 입고 후드티는 L로 입는 것을 예로 들 수 있습니다. 옷 종류에 따라 사이즈는 다르게 표기할 수 있는 것이죠.
또한 국가별로 표기법에 차이가 있습니다. 국내 여성복 95 사이즈는 미국에서는 6, 영국은 10-12, 프랑스는 38로 표기됩니다. 문제는 국내에 들어온 다수의 해외 브랜드가 의류 사이즈를 한국 표준으로 변환하여 표기하지 않다는 점입니다.
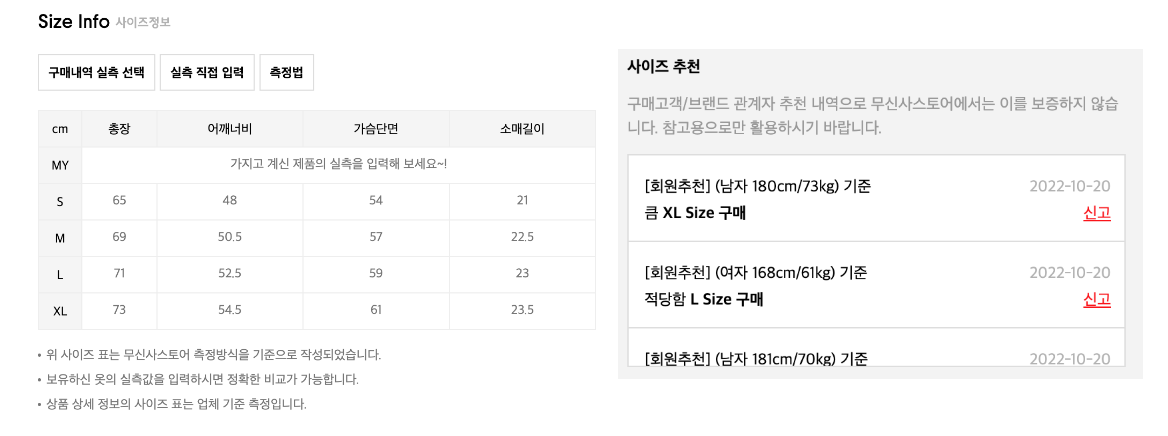
즉, 국가마다 사이즈 표기법이 다르고 표준이 있다고 해도 권고 사항 정도니, 옷 제조사 마음대로 옷의 사이즈를 표기해도 상관없다고 볼 수 있습니다. 의류 사이즈가 다른 이유입니다. 결론적으로 사이즈 표기법이 다양한 만큼 혼란스러운 거는 디젤리(소비자)의 몫입니다. 그래서 무신사와 같은 온라인 패션 플랫폼에서는 의류 치수를 직접 측정하여 제공하고 있습니다. 다른 사람이 직접 구매해서 입어본 사이즈 추천 리뷰도 제공하죠. 이처럼 의류 제조사에서 정의한 일관성 없는 사이즈에 실제 측정과 착용 데이터를 부가적으로 제공함으로써 구매에 도움을 주는 겁니다.
그래서 궁금증이 이어집니다. 의류 사이즈만 확인하고 옷을 구매하는 건 어려운 일일까요? 이를 확인해보고자 의류 사이즈에 대한 데이터를 다양한 방법으로 분석하여 알아보겠습니다.
………
의류 사이즈의 다양한 정보를 알기 위해 무신사 데이터를 수집해 분석하기로 합니다. 무신사에서는 다양한 브랜드를 판매하고 무엇보다 동일한 측정기준으로 의류 치수를 쟀다는 점에서 다양한 분석을 할 수 있다고 판단했습니다.
데이터는 다다익선이니, 우선 무신사에서 판매하는 모든 의류 종류와 모든 제품을 크롤링하기로 마음먹습니다. 수집 대상의 의류 종류는 속옷, 모자, 양말, 신발 등의 액세서리류를 제외한 상의, 아우터, 바지, 원피스, 스커트, 스포츠 카테고리입니다.
카테고리별로 제품 목록 페이지에서 제품 코드를 수집하는 크롤링 작업을 1차 진행하고, 제품 코드로 제품 상세 페이지를 조회하여 1) 제품 정보 2) 리뷰 정보 3) 구매 정보를 총 3번 호출하여 데이터를 수집합니다. 문제없이 크롤링하는 와중에 에러가 떠서 확인해보니 무신사 제품 목록 페이지가 최대 400페이지밖에 조회할 수 없다는 점을 발견하였습니다. 결국 ‘무신사 추천순’ 기본 정렬 기준으로 최대 400페이지까지 조회한 제품을 수집하였고, 총 337,247개의 상품입니다.
CATEGORY_CODE_LIST = ["001", "003", "020", "022", "002"]
for cat in CATEGORY_CODE_LIST:
print(f"{cat} starts crawling")
end_page = int(getEndPage(cat)["end_page"])
if end_page > 400:
end_page = 400
os.makedirs(f"crawl_data/pages_22.09.21/{cat}", exist_ok=True)
for page in tqdm(range(1, end_page + 1)):
saveProductLinks(category_code=cat, page=page)
전반적으로 사이즈에 영향을 줄 만한 데이터를 모두 수집합니다. 크롤링한 데이터 항목은 의류 정보(카테고리, 제품명, 브랜드, 품번, 성별, 컬러 옵션 등), 사이즈 정보(사이즈, 총장, 어깨너비, 가슴단면, 소매길이 등), 사이즈 가이드 정보(스키니 핏, 오버 사이즈, 신축성 정도, 계절감, 소재 신축성, 비침 정도), 구매 정보(누적 판매 수, 구매 후기 수, 인기 구매 연령대, 성별 등), 사이즈 추천 정보(구매자 키, 몸무게, 사이즈 커요, 작아요 등)를 포함합니다.
데이터를 직접 크롤링하여 수집할 때 웹에 있는 구조화되지 않은 정보를 분석 목적에 맞게 정형화하는 과정이 필요합니다. 단순히 행과 열로 구성된 데이터 형태를 만드는 작업만 하는 것이 아니라, 변수(열)마다 수집하고자 한 데이터가 잘 담겨있는지 확인하고 정제하는 과정을 포함하는데요.
무신사 데이터를 전처리하는 과정 중에서 가장 어려웠던 점은 사이즈 변환이었습니다. 사이즈가 다양한 값으로 작성되어 있어 일관된 형태로 변환하는 텍스트 정제 작업에 시간이 가장 많이 소요되었습니다. 무신사에서 사이즈 표로 제공하는 데이터였으므로 어느 정도 사이즈 기입 방식에 통일성이 있을 것이라고 예상하였는데 그렇지 않은 게 함정이었죠.
# 사이즈 표기법 통일하는 과정 예시, 예외 케이스를 직접 변환
def sizing_map(df_col):
SIZE_LABEL_MAP = {
# 1. FREE SIZE
"옵션없음": "FREE",
"SIZE": "FREE",
"단품": "FREE",
"아이보리": "FREE",
"ONE": "FREE",
"OS": "FREE",
"ONE-SIZE": "FREE",
"F": "FREE",
"LIGHT GREY/ONE": "FREE",
"프리사이즈": "FREE",
"원사이즈": "FREE",
"IVORY": "FREE",
"기모X": "FREE",
"기모O": "FREE",
"0 3 데빌 캣 튜브탑": "FREE",
"3 뉴스페이퍼 튜브탑": "FREE",
...(생략)
# 2. 문자 SIZE
"EXTRA SMALL": "XS",
"XSMALL": "XS",
"XSS": "XS",
"(UNISEX) 클래시 체크 셔츠 VER2_딥/M": "M",
"SMALL": "S",
"SS": "S",
"SSS": "S",
"1사이즈(M)": "M",
"XL-XL": "XL",
...(생략)
# 3. 숫자 SIZE - 폐지된 표기법 변환
"44": "85",
"55": "90",
"66": "95",
"77": "100",
"88": "105",
}
df_col = df_col.replace(SIZE_LABEL_MAP)
return df_col
사이즈가 컬러로 작성된 경우가 다수 있었는데, 실제 제품을 확인해보니 단일 사이즈라서 일일이 변경했습니다. 또, 영문과 숫자 사이즈를 모두 표기한 경우(예: L100) 영문 라벨링 된 사이즈를 우선 적용했습니다. 그 외 다양한 케이스가 있었으나 적절히 처리해서 무사히 브랜드가 라벨링 한 사이즈를 정제했습니다!
정제된 데이터의 특징을 파악하기 위해 사이즈 관련 통계량을 확인해봅니다. 무신사에서 수집한 의류는 남성복, 여성복, 그리고 성별 구분이 없는 유니섹스 복으로 나뉩니다. 성별에 따른 신체 크기에 차이가 있기 때문에 사이즈 데이터를 성별로 쪼개볼 필요가 있습니다. 참고로 남성복은 120,271개, 여성복은 70,091개, 유니섹스는 14,685개의 관측치를 갖습니다.
1) 유니섹스 의류는 남성복에 가깝다.
무신사에서 측정한 제품 실측 사이즈인 의류 치수를 활용하여 성별 치수 분포를 살펴보도록 하겠습니다. 상의와 아우터는 기본 신체 치수인 가슴둘레, 하의는 허리둘레를 기준으로 히스토그램을 그립니다. 의류 치수는 의도하지 않았지만 잘못 입력된 값의 케이스가 있어 이상치를 제거했습니다.
대체로 남성과 유니섹스 복은 분포 모양과 최빈값을 갖는 치수가 같아, 데이터의 형태가 비슷하다고 볼 수 있습니다. 반면 여성복의 경우 가슴둘레로 측정하는 상의와 아우터의 분포 범위가 넓지만 하의는 좁습니다. 즉, 여성복의 상의는 다른 성별에 비해 더 다양한 사이즈를 제공하지 않을까라고 생각해볼 수 있습니다.
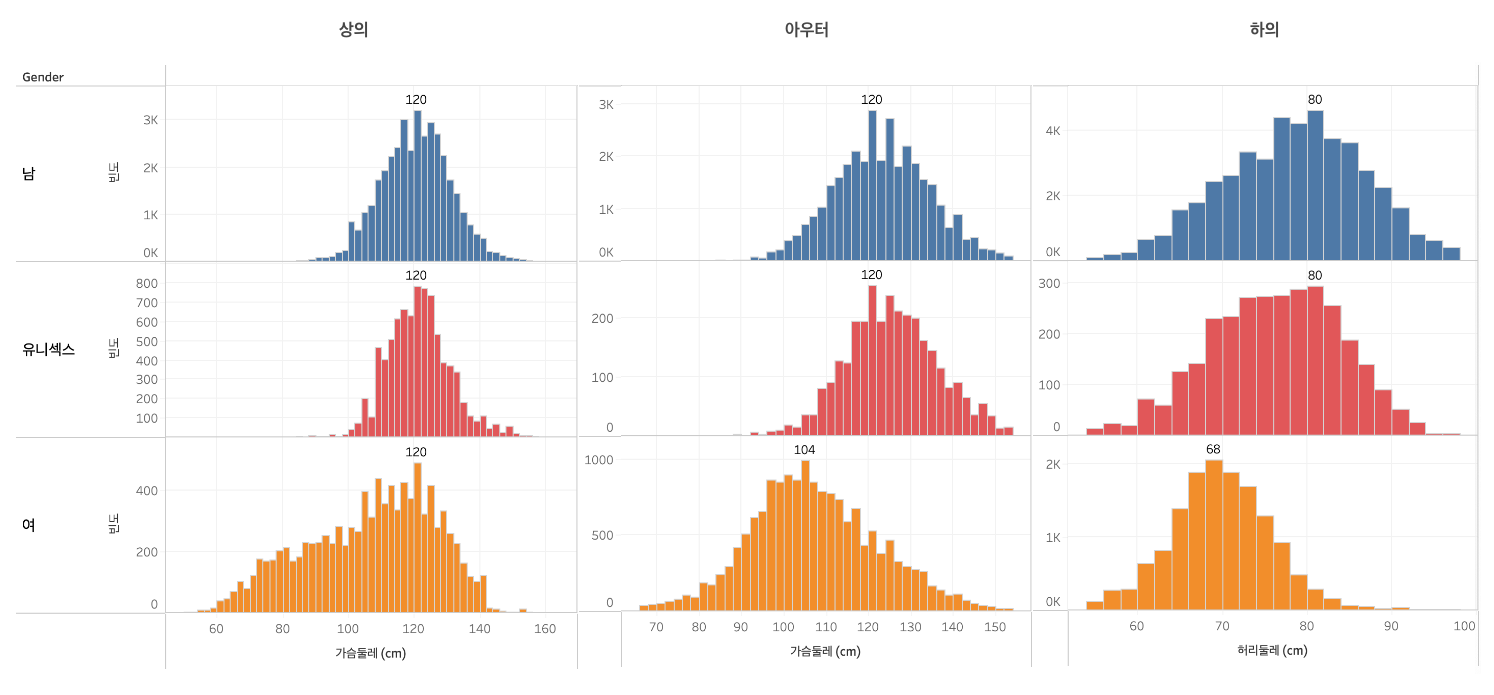
흥미로운 점은 상의의 경우, 여성복의 분포 모양은 다르지만 가장 높은 지점의 도수가 가슴둘레 120cm로 모든 성별이 동일했습니다. 이는 성별에 상관없이 가슴둘레 120cm인 제품이 가장 많다는 뜻인데요. 그러면 브랜드가 라벨링 한 사이즈 기준으로 보면 어떨까? 하는 궁금증이 생겼습니다.
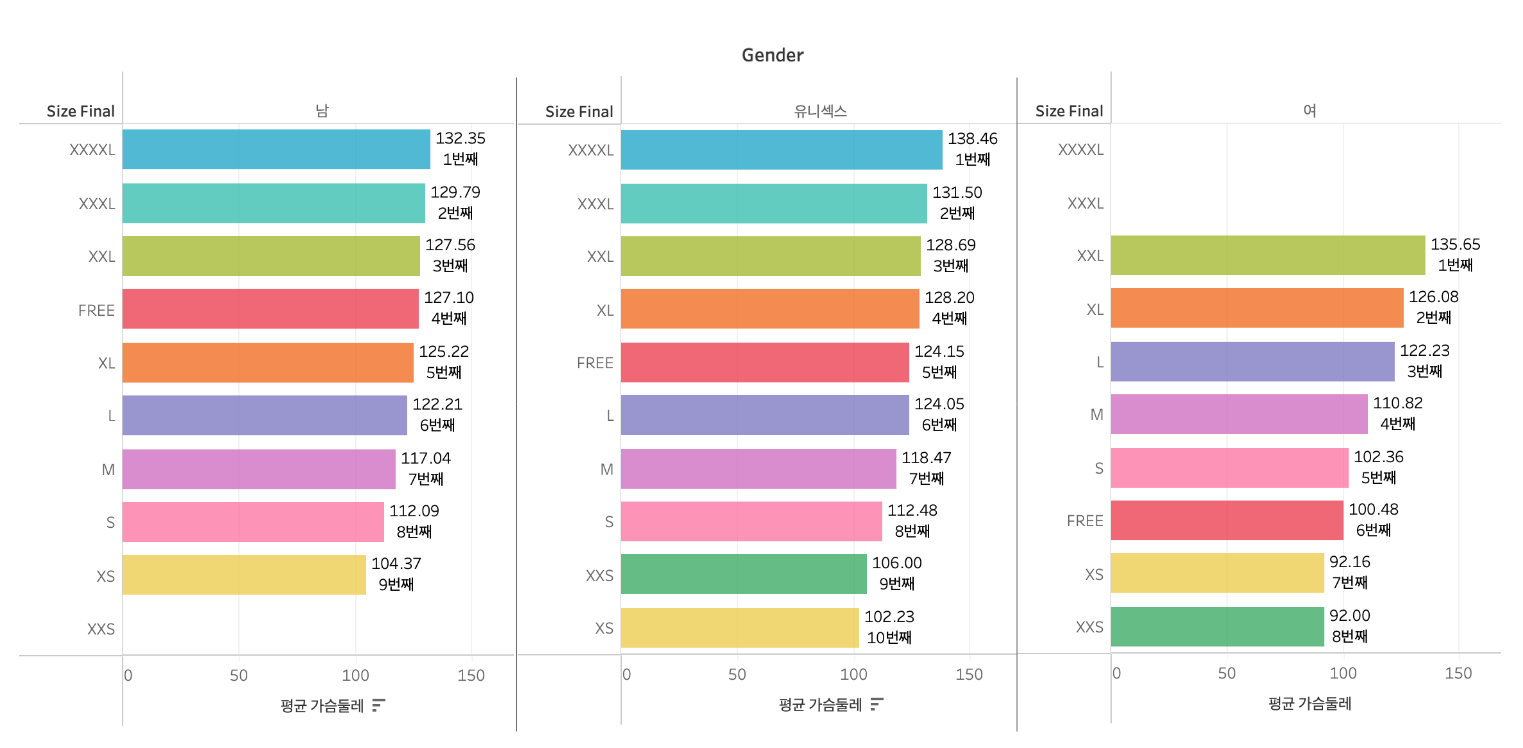
2) L 이상 사이즈 상의는 모든 성별이 입어도 맞다.
이번에는 사이즈 기준으로 의류 치수 평균을 알아보겠습니다. 대표적으로 영문 사이즈 라벨링을 한 상의 데이터만 살펴보았는데요. 사이즈가 작아질수록 평균 가슴둘레 또한 작아지는 패턴을 확인할 수 있습니다. 이는 사이즈 라벨링이 실측 사이즈의 크기 차이를 잘 반영한다고 볼 수 있습니다.
또 다른 인사이트로는 전반적으로 유니섹스는 남성복보다 평균 가슴둘레가 조금 더 큰 편으로 나타났고, 여성복 또한 L 사이즈 이상(XXL, XL, L)에 한정하여 남성복보다 컸습니다. 즉, L 사이즈 이상의 상의 치수는 여성복과 유니섹스 모두 남성복보다 컸는데요. 평균값이라 일반화하기엔 무리가 있지만, 여성복의 L 사이즈는 남성복만큼이나 크게 제작되어 모든 성별이 입어도 맞습니다.
3) 대부분의 여성복은 1개의 사이즈만 제공한다.
그렇다면 브랜드는 얼마나 다양한 사이즈를 제공할까요? 브랜드는 제품당 평균 2.45개의 사이즈를 제공하는 것으로 나왔습니다. 성별로 쪼개보면 유니섹스는 3.19개, 남성복은 3.08개, 여성복은 1.74개 순이었는데요. 유니섹스는 남성복과 비슷한 수준의 사이즈 개수를 제공하는 반면 여성복은 확실히 그 수가 적은 것을 알 수 있습니다.
더욱 보편적인 제공 개수를 알기 위해 평균이 아닌 최빈값으로 살펴보겠습니다. 결과는 의류 종류(상의, 하의, 아우터)에 따른 값의 차이보다 성별에 따른 차이가 명확한데요. 여성복의 경우 스커트를 제외하고 모두 한 개의 사이즈만 제공하여 여성복에만 사이즈 다양성이 적다는 것을 알 수 있습니다.
# pd.groupby 함수를 활용하여 통계 테이블 출력하기
df_items_sizing[[
"goodsNo_code",
"size_label",
"category_1",
"gender"
]].dropna(
subset="size_label"
).groupby([
"goodsNo_code",
"category_1",
"gender"
]).count().reset_index(
drop=False
).groupby([
"category_1",
"gender"
]).agg(
lambda x: pd.Series.mode(x)[0]
).sort_values(
["category_1", "gender"]
)[["size_label"]]
# size_label
# category_1 gender
# 상의 남 3
# 여 1
# 유니섹스 4
# 스커트 여 2
# 아우터 남 3
# 여 1
# 유니섹스 3
# 원피스 여 1
# 하의 남 3
# 여 1
# 유니섹스 3
한가지 사이즈만 제공하는 브랜드가 의도적으로 단일 사이즈로 제작한 것인지 더 정확하게 알아볼 필요가 있습니다. 왜냐하면 무신사에서 품절된 사이즈를 목록에서 제외하거나 애초에 일부 사이즈만 판매할 가능성이 있는 등, 다양한 이유가 있을 수 있기 때문인데요. 그래서 브랜드가 직접 명시한 단일 사이즈, 즉 프리사이즈의 비율을 계산해보았습니다.
여기서 정확한 프리사이즈 데이터는 브랜드가 사이즈를 직접 ‘프리사이즈’ 혹은 ‘원사이즈’로 명시하거나 사이즈를 별도로 표기하지 않아 애초에 단일 사이즈로 제작된 경우 ‘옵션없음’의 비율입니다. 예를 들어 브랜드가 의류를 단일 사이즈로 제작하였으나 사이즈 라벨을 ‘M’으로 명시한 경우는 포함되지 않습니다.
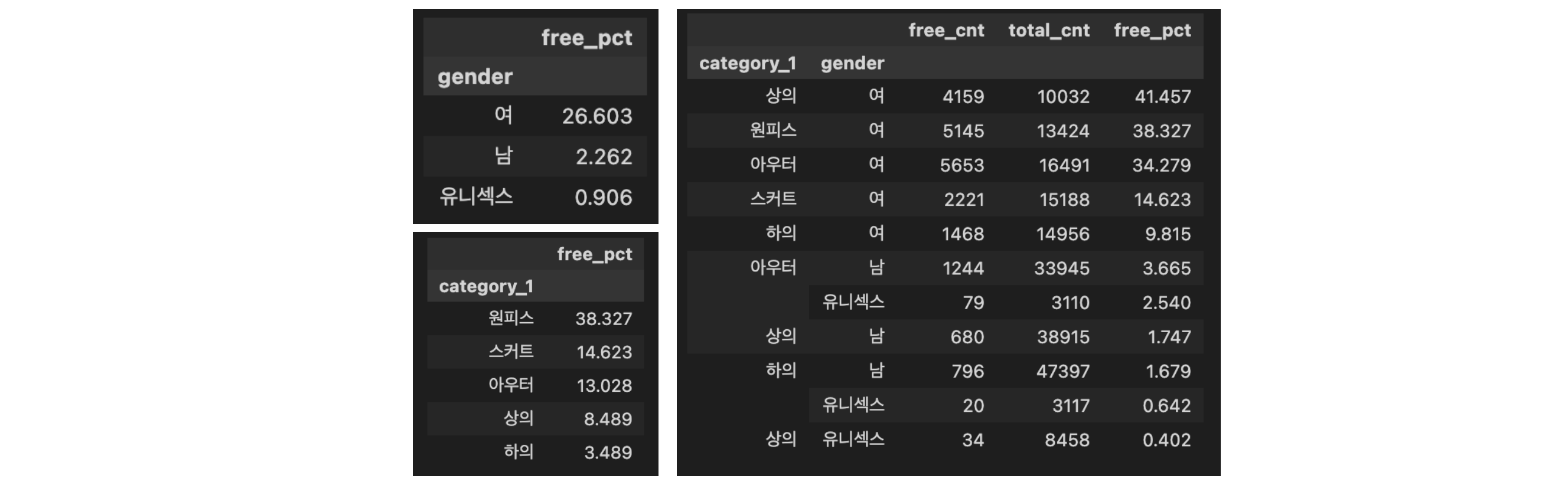
유니섹스의 프리사이즈 비율은 1%도 되지 않는 반면 여성복의 프리사이즈 비율은 26.6%로 2.3%인 남성복보다 13배 정도 많습니다. 의류 카테고리별로는 여성 전용 의류인 원피스와 스커트의 비율이 확실히 높았고, 여성복만 살펴보면 상의 41.5%, 원피스 38.3%, 아우터 34.3%로 상당한 비율이 단일 사이즈로 제작된 사실을 알 수 있습니다. 상당한 비율의 프리사이즈, 정체가 무엇인지 자세히 살펴보도록 하겠습니다.
………
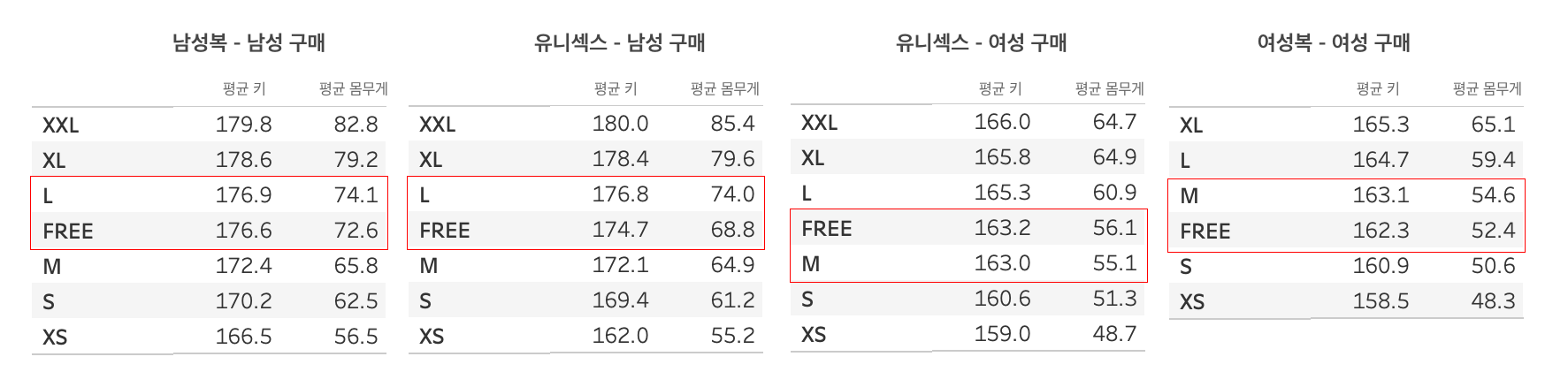
프리사이즈는 어떤 사이즈에 해당할지 상의 데이터만 한정하여 다양한 관점에서 유추해보겠습니다. 고려대한국어대사전에 따르면 프리사이즈는 보통 사람들의 평균 체형에 맞춘 의류로 정의합니다. 정의가 다소 주관적이라는 생각이 들지만, 일단 무신사에서 수집한 실구매 리뷰 데이터를 활용하여 ‘평균 체형’을 계산해보겠습니다. 프리사이즈 구매자의 평균 키와 몸무게에 가장 유사한 사이즈 1개를 꼽아보니, 아래와 같았는데요. 프리사이즈는 남자가 구매하면 L에, 여자가 구매하면 M 사이즈에 해당하는 것을 알 수 있습니다.
반면 업계에서는 프리사이즈를 가장 많이 판매되는 사이즈로 제작한다고 합니다. 다시 리뷰 데이터로 가장 많이 구매한 사이즈를 살펴보니 남성복과 유니섹스는 L, 여성복은 M 사이즈로 나타났습니다. 이는 구매자의 평균 체형 데이터로 확인했을 때와 동일한 결과임을 알 수 있습니다.
프리사이즈의 2가지 정의를 바탕으로 리뷰 데이터를 분석해보니 결과가 동일했고, 프리사이즈 남성복은 L, 여성복은 M 사이즈임을 유추할 수 있습니다. 하지만 리뷰 데이터는 보조적인 지표일 수밖에 없는데요. 어느 정도 구매가 이뤄져야 알 수 있는 정보이기 때문입니다. 그래서 보다 정확하게 브랜드에서 제공하는 의류 정보 데이터로 분석했을 시에도 동일한 결과가 나올지 살펴보겠습니다.
만약에 프리사이즈를 제작한 브랜드에 ‘프리사이즈를 호칭 사이즈로 변경해주세요’라고 강제성을 부여한다면? 즉, 프리사이즈를 브랜드에서 사이즈를 정의한 방식대로 라벨링 하면 과연 무엇일지 궁금해졌는데요. 직접 브랜드 관계자에게 물어봐서 정답을 얻으면 좋겠지만, 현실적인 어려움이 있으니 기계에 ‘네가 대신 브랜드 관계자처럼 행동해’라고 학습시키도록 하겠습니다. 브랜드가 지정한 호칭 사이즈 데이터로 지도 학습을 시켜 사이즈 분류기를 만듭니다. 여기에 사이즈 정답이 없는 프리사이즈 데이터를 전달하면 올바른 사이즈 라벨을 달아주는 것이죠.
앞서 프리사이즈의 비율이 가장 높았던 여성복 상의의 프리사이즈를 라벨링 하기 위해 상의 의류 사이즈를 예측하는 머신러닝 분류기를 만들어서 확인해보도록 하겠습니다! 여성과 남성복의 교차 구매가 이뤄질 수 있는 점을 고려하고, 데이터 셋 사이즈의 확보를 위해 전체 성별을 대상으로 한 상의 분류 분석을 합니다.
1) 타겟 변수 라벨링
상의 사이즈를 예측하는 분류기를 만드는 게 목적이므로 타겟 변수는 사이즈입니다. 사이즈 클래스는 KS 표준 ‘범위 표시 치수 분류표’에 맞춰 남성복과 유니섹스는 M~XL, 여성복은 S~XL로 구분하되, 해당 클래스 범위 밖의 사이즈는 S-, XL+와 같이 라벨링 하여 이하와 이상의 범위를 표시합니다. 앞서 데이터 기술 통계(인사이트 도출) 단계에서 유니섹스 데이터가 남성복과 유사한 특징을 갖는 것을 확인하였기 때문에 남성복과 유니섹스 복은 같은 기준의 클래스로 구분합니다.
## 사이즈 없는 경우, 제외
df_shirts = df_shirts[df_shirts["size_final"].notnull()]
# 범위 사이즈, 제외: 'S-M'사이즈 3 records
df_shirts = df_shirts[df_shirts["size_final"] != "S-M"]
# 사이즈 라벨링 통일
repl_map = {
"XXL": "XL+",
"XXXL": "XL+",
"XXXXL": "XL+",
"XXL-XXXL": "XL+",
"XS": "S-",
"XXS": "S-",
"95-100": "98",
"100-105": "103",
"105-115": "110",
"95-105": "100",
"105-110": "108",
"85-95": "90",
}
df_shirts["size_final"] = df_shirts["size_final"].replace(repl_map)
# 라벨링이 필요한 테이블 분리
not_convert = ["XL+", "XL", "L", "M", "S", "S-", "FREE"]
df_in = df_shirts[df_shirts["size_final"].isin(not_convert)]
df_not = df_shirts[~df_shirts["size_final"].isin(not_convert)]
# target 변수 생성 - 숫자 라벨 사이즈를 호칭 사이즈로 라벨링
df_not["size_target"] = np.NaN
df_not["size_final"] = df_not["size_final"].astype("int")
# 여
bins = [-1, 71, 81, 88, 97, 108, 1000]
labels = ["S-", "S", "M", "L", "XL", "XL+"]
df_not["size_target"] = df_not["size_target"].fillna(
pd.cut(df_not[f]["size_final"], bins=bins, labels=labels)
)
# 남/유니섹스
bins = [-1, 84, 92, 100, 107, 1000]
labels = ["M-", "M", "L", "XL", "XL+"]
df_not["size_target"] = df_not["size_target"].fillna(
pd.cut(df_not[m]["size_final"], bins=bins, labels=labels)
)
df_not["size_target"] = df_not["size_target"].fillna(
pd.cut(df_not[uni]["size_final"], bins=bins, labels=labels)
)
# 최종 사이즈 테이블 생성
df_in["size_target"] = df_in["size_final"]
df_shirts_final = pd.concat([df_in, df_not], axis=0)
최종적으로 사이즈를 S-, S, M- M, L, XL, XL+ 클래스로 분류한 후, 클래스 간 수치형 변수의 평균에 차이가 있는지 확인하였는데요. M- 사이즈와 M 사이즈의 가슴둘레 평균 차이가 크지 않아, 클래스 분류가 더 잘될 수 있도록 ‘M-’을 ‘M’으로 변경하여 같은 그룹으로 통합하였습니다.
2) 변수 생성 feature engineering
분류 분석에 앞서 정제된 데이터 중 사이즈에 영향을 줄 만한 요소를 별도 피처(feature, 변수)로 생성하는 작업을 합니다. 예를 들어 탄력성이 있는 소재로 제작한 상의는 작아 보이지만 착용했을 때 맞을 수 있으므로 피처를 따로 만들었는데요. 소재에 스판과 폴리우레탄이 포함된 경우에 탄력성이 있는 의류라고 판단하여 is_flexible에 True값을 부여했습니다. 그 외 탄력성이 없는 소재인 폴리에스터가 포함된 경우 is_poly라는 피처를 만드는 등의 작업을 했습니다. 또한 스포츠웨어는 일상복보다 정 사이즈로 입을 수 있어서 스포츠웨어인지의 여부를 알 수 있는 변수(is_sportswear)로 변환합니다.
3) 분류 모형 학습 및 최적화
클래스의 개수가 많다보니 분류가 잘 될 수 있도록 비선형 분류 모형을 위주로 학습시켰습니다. 우선 모든 피처를 하이퍼 파라미터를 조정하지 않은 기본 모형에 학습한 후, 최적화 작업을 합니다.
lrc = LogisticRegression() svc = SVC() dt = DecisionTreeClassifier() rfc = RandomForestClassifier(random_state=42) xgb = XGBClassifier()
최적의 피처 개수 및 조합을 도출 후 가장 점수가 높은 모델, XGBoost를 학습하는 과정을 반복하였는데요. 총 33개의 피처 중 17개의 피처를 사용하였고, 최종 선택된 피처는 아래와 같습니다.
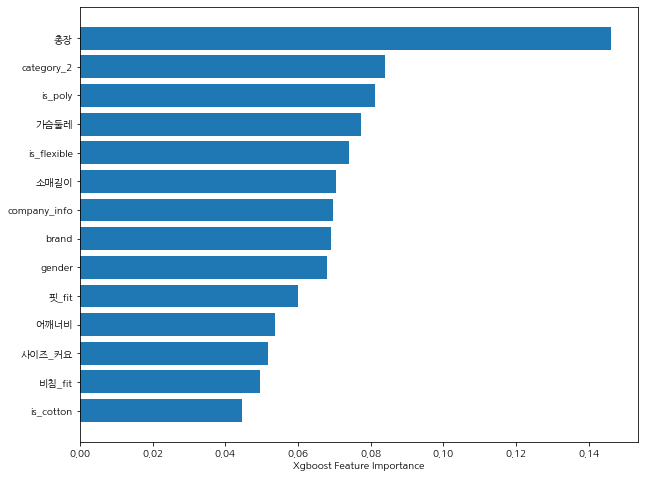
사이즈 분류에 가장 큰 영향을 미친 피처는 ‘총장’이었는데요. 예상외로 ‘가슴둘레’ 치수보다 ‘총장’의 길이가 더 사이즈 분류를 명확히 구분하는 요인으로 나타났습니다. ‘총장’ 다음으로는 피처의 중요도가 엇비슷한 수준이었으나 ‘category_2’, ‘is_poly’, ‘가슴둘레’ 순이었습니다. 옷의 종류에 따라, 그리고 신축성이 없는 소재(poly, 폴리에스터)의 포함 여부에 따라 사이즈가 다르게 결정된다는 점을 알 수 있습니다. 또 흥미로운 점은 옷을 제작하는 기준에 따라 사이즈를 다르게 기재할 수 있을 텐데요. 사이즈 분류에 회사(company_info)와 브랜드(brand)가 영향을 주는 것으로 나와, 옷 제조사에 따라 사이즈 분류가 달라질 수 있다는 것을 확인할 수 있습니다.
# category_2(옷의 종류)의 세부 항목 df_shirts["category_2"].unique() # array( # [ # "니트/스웨터", # "반소매 티셔츠", # "맨투맨/스웨트셔츠", # "피케/카라 티셔츠", # "긴소매 티셔츠", # "셔츠/블라우스", # "후드 티셔츠", # "기타 상의", # "민소매 티셔츠", # ], # dtype=object, # )
4) 분류 모형 평가
최종 점수를 내기 전에 검증 데이터 셋으로 분류 모형의 성능 평가 점수를 확인합니다. 모든 클래스의 정밀도(precision)는 0.7을 넘어 어느 정도 모형이 정답지를 올바르게 검출한 것을 알 수 있습니다. 그러나 Small 이하 사이즈인 S-의 재현율(recall) 점수가 매우 낮았는데요. 이는 관측치 수(support)가 140개로 매우 낮아 충분한 학습을 하지 못한 것으로 볼 수 있습니다. 해당 클래스를 제외하고는 정밀도와 재현율을 종합적으로 평가한 f1 스코어를 반올림하여 보면 0.8을 넘는 수준입니다. 클래스별 개수의 차이가 있어 가중 평균으로 확인할 필요가 있으며, 최종 f1 스코어는 0.8170입니다.
# 검증 데이터셋으로 산출한 점수
print(classification_report(
y_val, xgb5_prd, target_names=encoder.classes_, digits=4
))
# precision recall f1-score support
# L 0.8130 0.8178 0.8154 3249
# M 0.7944 0.8042 0.7992 2911
# S 0.8208 0.8157 0.8182 1595
# S- 0.7128 0.4786 0.5726 140
# XL 0.8215 0.8541 0.8375 1967
# XL+ 0.9287 0.8368 0.8803 778
# accuracy 0.8174 10640
# macro avg 0.8152 0.7678 0.7872 10640
# weighted avg 0.8178 0.8174 0.8170 10640
최종 평가 데이터셋으로 예측한 모형의 평가 점수는 아래와 같습니다. F1 스코어는 약 0.82, ROC AUC 스코어는 약 0.97입니다. 해당 점수는 학습시킨 분류기가 사이즈 라벨링을 나쁘지 않게 예측하였고, 프리사이즈 의류를 라벨링을 해봐도 의미 있는 결과를 기대해볼 수 있다고 판단하였습니다.
# 평가 데이터셋으로 산출한 최종 점수
# 최종 모형
xgb5 = XGBClassifier(
n_estimators=700,
learning_rate=0.15,
max_depth=7,
random_state=42
)
# 최종 점수 - f1 score
xgb5_final = xgb5.predict(X_test)
print(f1_score(y_test, xgb5_final, average='weighted'))
# 0.8195403944763383
# 최종 점수 - roc auc score
xgb5_final_proba = xgb5.predict_proba(X_test)
print(roc_auc_score(y_test, xgb5_final_proba, multi_class='ovr'))
# 0.9691912542684166
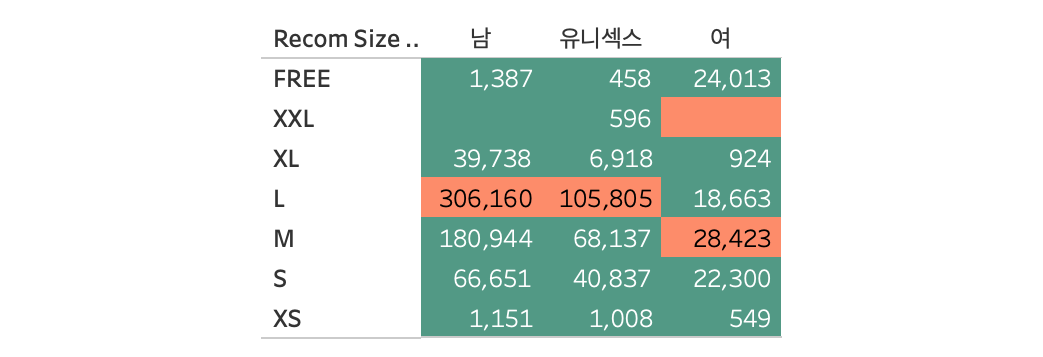
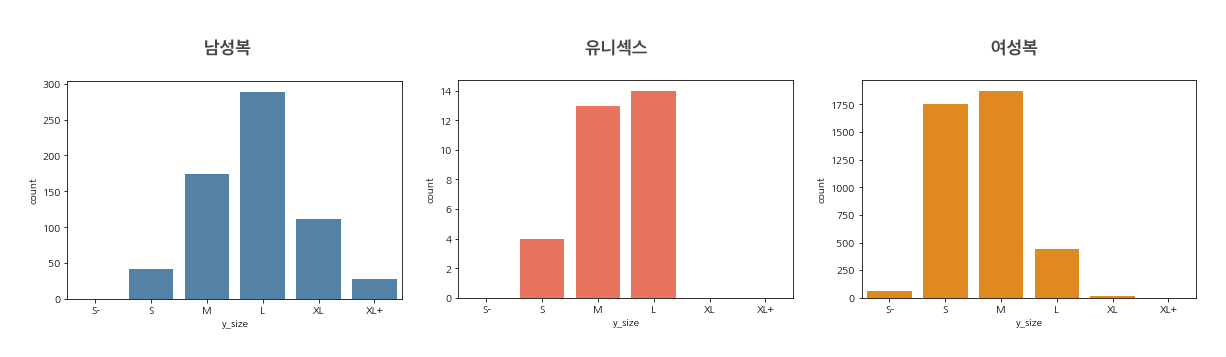
드디어 긴 머신러닝 여정의 마지막 단계! 아래는 상의 의류 사이즈 분류기에 ‘FREE’ 라벨 사이즈를 예측해본 결과입니다. 프리사이즈는 남성복 및 유니섹스의 경우 L 사이즈, 여성복의 경우 M 사이즈에 가장 많이 해당합니다. 다만 여성복은 총 4,149개의 프리사이즈 중에서 45.1%가 M 사이즈, 42.2%가 S 사이즈로 나온 만큼 프리사이즈는 S와 M 사이즈로 제작되는 비중이 거의 비슷하다고 이해하는 게 정확합니다. 또한 유니섹스의 프리사이즈는 총 31개밖에 되지 않아, 해당 결과에 해당한다고 결론짓기에는 무리가 있습니다.
………
직접 수집한 의류 데이터를 다양한 방법과 관점에서 분석하여 사이즈에 대한 여러 가지 궁금증을 확인해보는 시간이었는데요. 브랜드가 정의한 사이즈 호칭대로 나의 사이즈를 정의하진 말아야겠다는 생각이 들었습니다. 프리사이즈를 입어서 사이즈가 맞지 않은 경우에도, 섣부르게 나의 체형을 남과 비교할 필요도 없겠다는 생각과 함께요. 사이즈는 생각보다 옷의 종류, 소재 그리고 브랜드마다 상이하여 구매 시 다양한 요소를 고려해야 합니다.
이번 콘텐츠에 영감을 준 디젤리님의 첫 번째 궁금증, ‘왜 브랜드마다 사이즈가 다른지 궁금했습니다’는 근본적으로 의류 사이즈는 표기법이 다양하기 때문에 다를 수밖에 없다는 점을 알아보았습니다. 그리고 실제로 브랜드마다 사이즈가 다른 게 맞다고 피처 중요도를 통해 확인할 수 있었습니다.
XL을 입는 디젤리님이 상의 티셔츠를 산다면… 아래 내용 정도로 꿀팁을 전달해드릴 수 있을 것 같습니다.
무신사가 제공한 다양한 의류, 리뷰 데이터가 사이즈 예측에 도움이 된 만큼 원하는 사이즈를 구매할 수 있도록 도움을 주지 않을까 생각합니다. 다만, 유의할 점은 무신사에서 수집한 제품 중 대다수가 국내 스트릿 브랜드였기 때문에 위 분석 결과를 다른 의류에 일반화하는 데 무리가 있음을 참고해주세요. 그럼 다음번에도 흥미로운 주제로 찾아오겠습니다!

















소셜댓글